
ChatGen:自动化文生图系统

论文题目:ChatGen: Automatic Text-to-Image Generation From FreeStyle Chatting
论文地址:https://arxiv.org/abs/2411.17176
项目地址:https://chengyou-jia.github.io/ChatGen-Home/
1 引言
文本到图像(T2I)生成模型因其图像的高质量和文本对齐能力而受到极大关注。尽管开源模型的发展为用户提供了广泛的定制化选择,但同时也给普通用户带来了显著的学习挑战。用户在创建具有特定需求的图像时,常常需要经历多个复杂且不确定的步骤,例如制定合适的提示词、选择合适的模型及配置特定参数,整个过程既繁琐又耗时。为了解决这一问题,我们提出了一个全新的挑战:能否自动化文生图过程中的繁琐步骤,使用户仅需通过聊天方式简单描述其需求,便能轻松获得所需图像?

2 自动化T2I生成基准:ChatGenBench
我们首先提出了一个专为自动化T2I生成任务设计的新型基准数据集。它包含了大量高质量的配对数据,这些数据覆盖了多样化的自由风格用户输入,使得研究者能够全面评估自动化T2I模型在各个步骤中的性能。每个数据对包括用户的自由风格聊天输入、经过精炼的提示词、适当的模型选择,以及最优的参数配置,为自动化T2I模型的评估提供了一个步骤化的评估路径。
该数据集的构建如下图所示,主要涉及两个关键部分:高质量人类示范收集和使用大语言模型驱动的角色扮演来模拟用户输入。高质量人类示范收集确保了数据集中包含的每个示例都能够代表真实世界中高效和准确的T2I生成需求。这些示范通过严格的质量控制流程筛选,确保数据的可靠性和有效性。而LLM驱动的角色扮演则通过模拟各种日常生活中的角色,如学生、医生和教授等,将这些示范转换为自由风格的聊天输入。这种方法显著增强了数据的多样性和现实感,为自动化T2I模型提供了丰富和真实的训练材料。
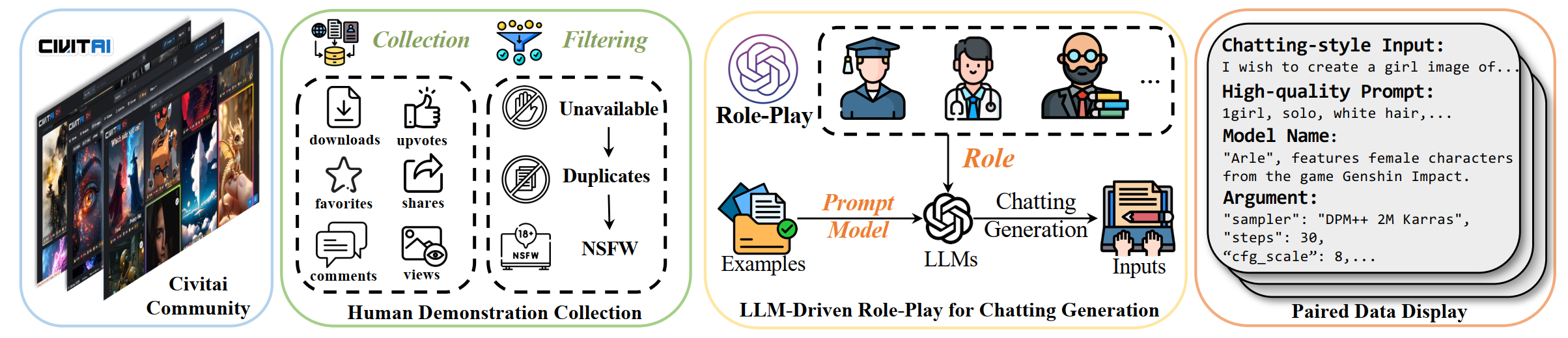
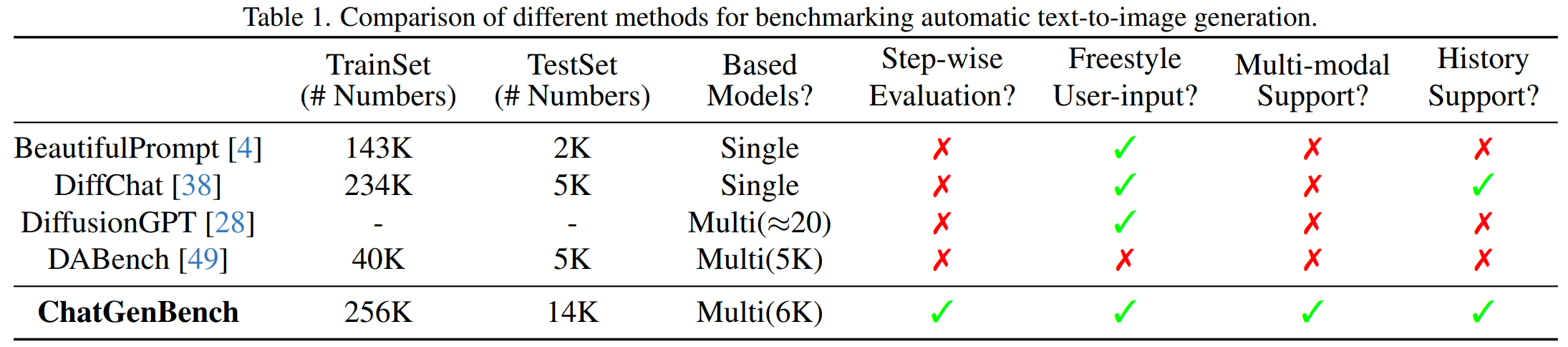
此外,ChatGenBench集成了各种类型的数据,包括单一输入、多模态输入,以及具有对话历史的输入,以模拟实际应用场景。这种设计不仅增加了数据集的实用价值,而且通过精确的标定和系统化的分析,揭示了潜在的自动化瓶颈,从而推动了自动T2I技术的发展。通过这一基准测试,研究人员可以更深入地理解和优化自动化T2I生成过程,从而推动自动化图像生成技术向前发展。比起之前的数据集基准,ChatGenBench的优势总结如下:
3 多阶段进化训练策略:ChatGen-Evo
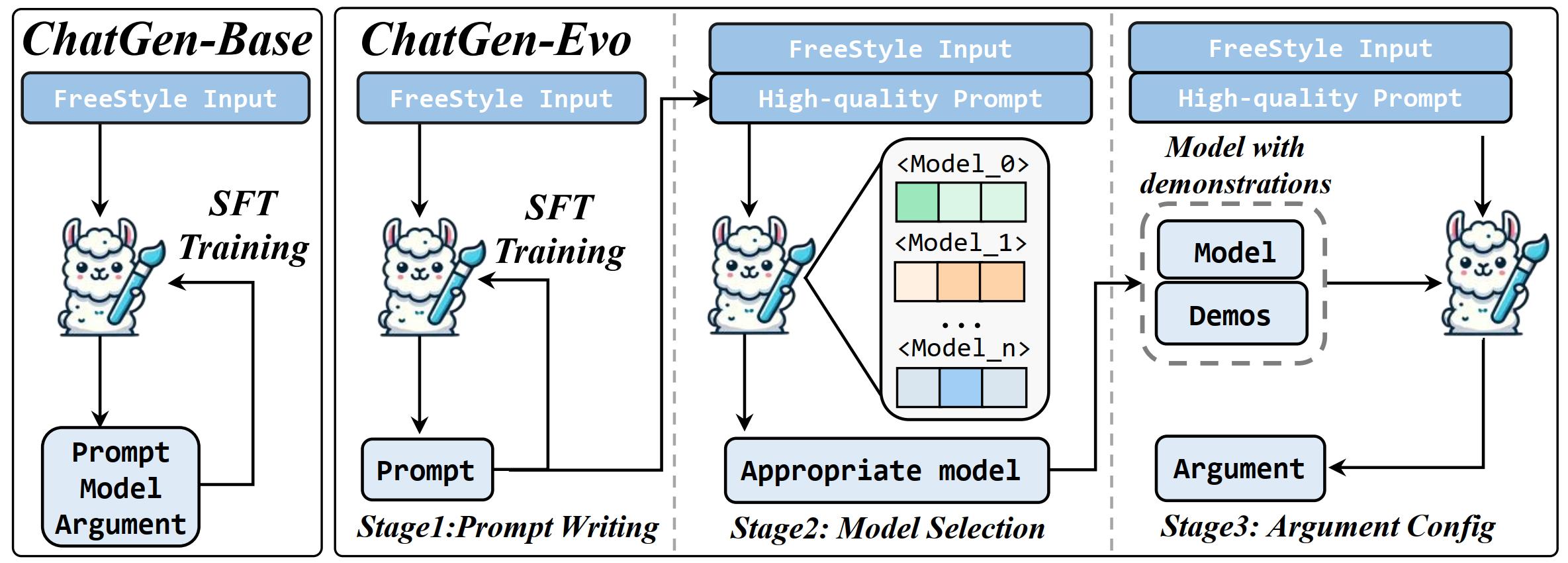
该研究的目标是训练一个能够处理自由风格用户输入$c$并生成图像生成所需的各个组成部分(提示词$p$、模型$m$和参数$a$)的模型,从而实现自动化的文本到图像(T2I)转换。为此,我们提出了ChatGen-Evo,采用一种创新的多阶段进化训练策略,旨在逐步培养模型完成自动文本到图像(T2I)生成所需的关键技能。这种方法通过将整个生成任务分解为几个清晰定义的阶段,每个阶段都专注于培养模型的一个特定能力,从而实现高效且目标明确的训练。
3-1 SFT实现提示词改写
在此阶段,模型首先接受训练,以便从用户的自由风格输入中生成高质量的提示词。这一过程利用监督式微调(SFT)技术,确保生成的提示词能够准确反映用户的需求。
\[L_{sft}^{stage1} = -\sum_{t} \log P_{\pi}(p \mid c', *_{<t}).\]3-2 ModelToken实现模型选择
经过初步的训练后,模型在第二阶段学习如何根据生成的提示词选择最合适的T2I生成模型。这一阶段引入了“模型令牌”(ModelToken)策略,通过扩展语言模型的词汇表来包含特定的模型令牌,使模型能够有效地识别并选择适当的图像生成模型。
ModelToken训练
在训练过程中,用户输入 $c$ 和提示词$p$被拼接作为前缀,特殊的模型令牌
模型挑选推理
一旦ModelToken训练完成,推理过程将模型令牌和原始词令牌进行拼接,形成多模态大语言模型(MLLM)的新语言模型头。通过这种方式,MLLM使用以下概率预测下一个词令牌:
\[P_{\pi}(m |c,p) = \text{softmax}([W_{\nu}; W_{\mathcal{M}}] \cdot h_{i-1})\]一旦预测出模型令牌,多模态大语言模型(MLLM)将停止解码,并选择相应的模型$m$。此外,还会加载模型的描述和示例等信息以供后续使用。在第二阶段之后,模型不仅保留了其提示词生成的能力,还学会了模型选择能力。
3-3 上下文学习实现参数配置
在成功选择模型后,最后一个阶段聚焦于根据所选模型和生成的提示词配置生成参数。这一阶段不再需要传统的训练,而是利用在上下文中的示范来引导模型完成参数的正确配置。
\[a = M(c, p, D(m))\]由于在前期阶段已经获取了相关模型和提示词,这种方法释放了上下文空间,使得可以进行更广泛的示例。此外,这种无需训练的方法避免了干扰前两个阶段已经训练好的模型。
4 主要实验
4-1 实验设定
在本研究中,本文通过在新型基准数据集ChatGenBench上进行广泛的实验来全面评估了自动文本到图像(T2I)生成模型的性能。我们首先比较了多阶段进化策略的ChatGen-Evo模型与基线模型。接着,我们进行了深入的消融研究,探讨了每个训练阶段对最终图像生成质量的具体影响,并通过逐步评估指标如Prompt BERTScore、模型选择精度和参数配置精度来验证模型性能。此外,我们还利用HPS v2、ImageReward、FID和CLIP Score等多种度量标准对生成图像的质量进行了综合评估。
4-2 主要实验结果
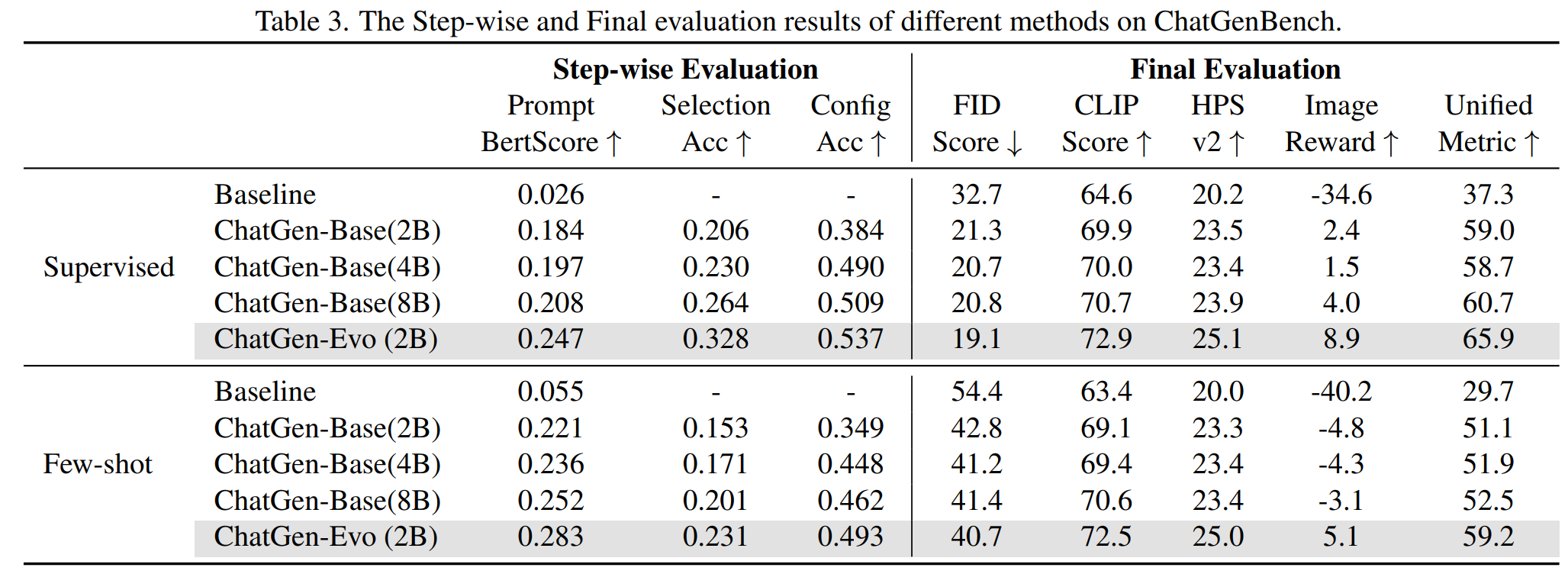
主表展示了ChatGen-Evo与其他Baseline模型的定量结果比较。总体而言,ChatGen-Evo在所有指标上,包括逐步和最终图像质量评估中,显著优于其他方法。具体来说,Baseline的低性能突显了有效的提示词重写和多模型选择的重要性,强调了专门的自动文本到图像(T2I)方法的必要性。此外,使用逐渐增大的参数规模(从2B到8B)对多模态大语言模型(MLLMs)进行微调,可以稳步提升性能。值得注意的是,尽管使用的参数规模仅为2B,ChatGen-Evo的性能与使用8B参数的ChatGen-Base相当。
4-3 人工评估
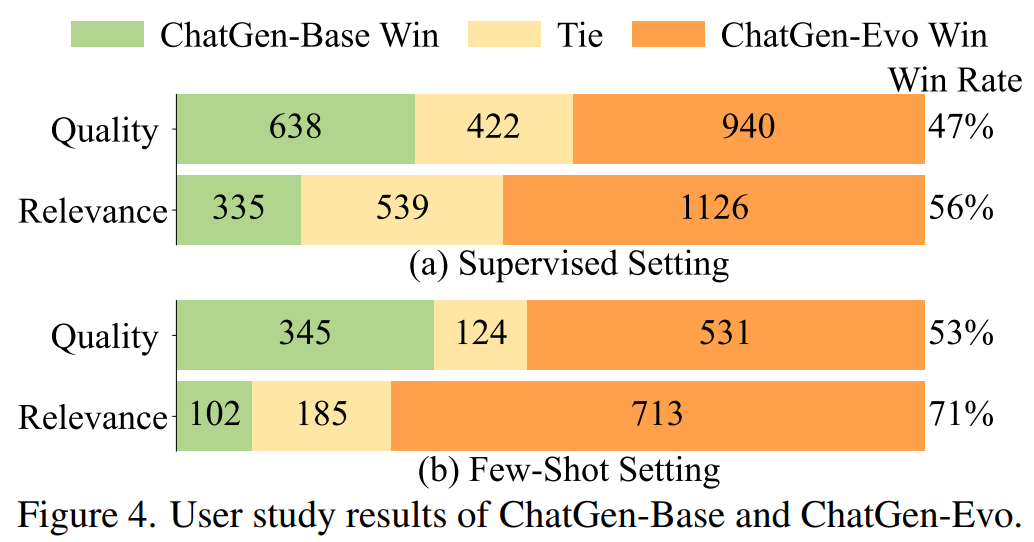
我们通过进行成对比较的用户研究,进一步评估ChatGen-Base(8B)和ChatGen-Evo(2B)。参与者将看到两幅从相同输入生成的图像:一幅由ChatGen-Base生成,另一幅由ChatGen-Evo生成。参与者的任务是选择更符合给定输入的图像质量和相关性的图像。我们为监督设置抽样了2000对图像,为少样本设置抽样了1000对。如图所示,人类评估结果与定量指标一致,突出显示了ChatGen-Evo在图像质量和相关性方面均优于ChatGen-Base。此外,在少样本设置中,ChatGen-Evo展示出更高的胜率,证明了ChatGen在数据稀缺场景下的有效性。
4-4 消融实验
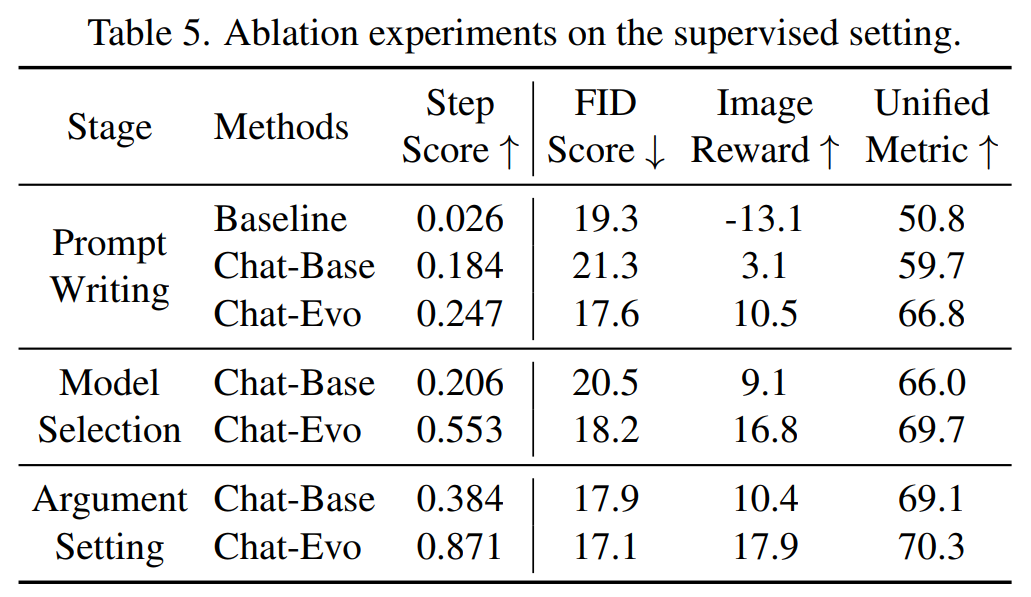
我们在ChatGenBench上进行了消融实验,以评估各个步骤对最终性能的贡献,同时为其他步骤提供了真值结果作为对比。实验表明,不同方法在提示词生成方面与经人工验证的提示相比存在显著差距,突显了提示词重写的复杂性。正确的模型选择和参数配置可以显著提升性能,尤其是在基线方法中。此外,提示词的变化对最终结果有重大影响,凸显了其在自动T2I中的关键作用。在模型选择方面,当提供精心制作的提示词和参数时,ChatGen-Evo显示出显著的性能提升,从32.8%提升到55.3%,验证了提示质量对模型选择精度的强烈影响。参数配置方面,ChatGen-Evo在提供高质量提示词和适当的模型选择后,展示出显著的性能改进,配置精度从53.7%提高到87.1%,统一评分从65.9提高到70.3。这些发现表明,早期步骤的结果显著影响后续步骤的预测,因此,探索更多的推理方法以推进自动化T2I是一个有前景的研究方向。
5 可视化结果展示
5-1 定性比较
下图展示了不同方法生成的图像示例。从第一行可以明显看出,ChatGen-Evo能够理解用户需求并识别合适的模型来生成风格匹配的图像。第二行展示了基于多模态用户输入的结果,其中ChatGen-Evo表现出对参考图像的深入理解,并保留了更多细节以生成更精细的输出。第三行则展示了ChatGen-Evo处理历史数据的能力,确保每个步骤都能继承之前的风格,同时根据用户需求进行适当的修改。这些展示不仅证明了ChatGen-Evo在理解和生成任务方面的高效性,也展示了其在不同类型输入处理上的灵活性和高适应性。

5-2 阶段输出展示
下图展示了ChatGen-Evo的逐步输出和最终图像。可以观察到,ChatGen-Evo能够根据用户的自由风格输入有效地重写高质量的专业提示词。此外,ChatGen-Evo选择适合的模型以匹配用户所希望的风格或特定角色。最后,它生成恰当的参数配置,以确保生成图像的高质量。通过精心设计的逐步输出产生的这些高质量图像,展示了自动文本到图像(Automatic T2I)的价值。它免去了用户进行繁琐步骤的负担,直接从他们的自由风格输入自动化地生成所需的图像。


5-3 与商用模型的比较
我们将我们的方法与先进的商业模型DALL-E 3的图像质量进行了比较。虽然DALL-E能够生成高质量的图像,但其风格主要局限于单一类型(动漫风格)。这一局限源于它依赖单一模型,无法完全适应多样化和个性化的风格。这突显了我们方法的价值,尤其是在需要真实风格或其他个性化输出的场景中,我们的方法表现得更为出色。

