
LD-DPO:基于 DPO 的长度脱敏偏好优化算法

论文题目:Length Desensitization in Direct Preference Optimization
论文地址:https://arxiv.org/abs/2409.06411
1 引言
大语言模型(Large Language Model, LLM)在自然语言处理(Natural Language Processing, NLP)领域已取得显著成就,不仅能够生成与人类相似的文本,还能理解复杂的上下文关系,并完成多样化的下游语言任务。为了确保模型行为符合人类的价值观及偏好,通过人类反馈进行的学习是至关重要的,它有助于提升模型的实用性、诚实性及安全性。直接偏好优化(Direct Preference Optimization, DPO)作为一种常用的偏好学习策略,与传统基于人类反馈的强化学习算法(Reinforcement Learning from Human Feedback,RLHF)不同,前者通过采用隐式奖励机制替代在线奖励模型(Reward Modeling, RM),从而简化训练过程并增强训练稳定性。
| 然而,经由一系列实证研究揭示,DPO方法在优化过程中倾向于过度强调文本的丰富性,导致模型输出过于冗长,进而影响了模型在部分下游任务(逻辑推理,封闭知识问答等)中的性能以及最终用户的体验。鉴于此,本文旨在探讨DPO优化目标中的潜在局限性,指出用于拟合隐式奖励的模型预测概率$\pi(y | x)$与输入序列长度之间存在着密切关联,即DPO算法存在无法避免的长度敏感性。基于上述发现,文中提出了一种名为长度脱敏直接偏好优化(Length Desensitized Direct Preference Optimization, LD-DPO)的偏好优化方法,以解决DPO算法存在的长度敏感性,鼓励模型学习长度偏好以外的真实人类偏好。 |
实验结果表明,在使用Llama2-13B、Llama3-8B及Qwen2-7B两类不同设置(Base版本和Instruct版本)的背景下,于MT-Bench与AlpacaEval 2等多个基准测试集中,相较于传统的DPO及其他基准方法,LD-DPO展现出了优越的表现。该方法不仅使得模型能够生成更为精炼且高质量的响应,相较于DPO方法,输出长度平均缩减了10%-40%,同时还在很大程度上提升了模型的逻辑推理能力。LD-DPO在多类任务上更好地实现了LLM与人类的偏好对齐。
文章的主要贡献如下:
- 文章首次定义了DPO的长度敏感性,并为这一现象提供了理论验证。
- 文章提出LD-DPO,一种长度脱敏的直接偏好优化算法,通过对预测概率的重新建模,缓解了DPO算法的长度敏感性。
- 文章通过实验验证LD-DPO算法能够使模型生成更简洁且高质量的回复,相比于DPO算法,响应长度减少了10%-40%。
2 DPO长度敏感性
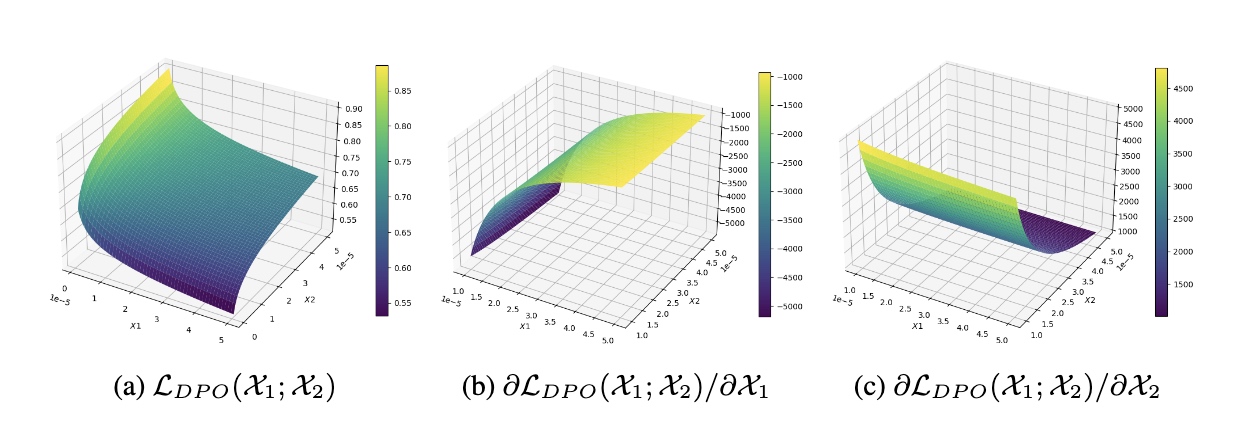
本文通过对DPO的损失函数(如下公式)进行理论分析,揭示了DPO算法的长度敏感性。 \(\mathcal{L}_{DPO}(\pi_\theta;\pi_{ref})= -\mathbb{E}_{(x,y_w,y_l) \sim \mathcal{D}}[\log\sigma(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)}-\beta \log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)})].\) 具体来说,针对由人类标注的偏好数据(Chosen)与非偏好数据(Rejected)组成的数据组合$(x,y_w,y_l)$,将actor模型的预测概率分别记作$\mathcal{X}1=\pi\theta(y_w|x)$和$\mathcal{X}2=\pi\theta(y_l|x)$,且将reference模型的预测概率分别记作$\mathcal{K}1=\pi{ref}(y_w|x)$和$\mathcal{K}2=\pi{ref}(y_l|x)$,通过对DPO的两个预测变量分别求解梯度,得到二者梯度的相对数值关系,具体如下所示: \(\left\lvert \frac{\partial \mathcal{L}_{DPO}(\mathcal{X}_1;\mathcal{X}_2)}{\partial \mathcal{X}_1}/\frac{\partial \mathcal{L}_{DPO}(\mathcal{X}_1;\mathcal{X}_2)}{\partial \mathcal{X}_2} \right\rvert = \frac{\mathcal{X}_2}{\mathcal{X}_1} = \frac{\pi_{\theta}(y_l|x)}{\pi_{\theta}(y_w|x)},\) 即,二者的梯度数值之比取决于actor模型的预测概率,而该预测概率可以看作是逐个token预测概率的连乘,即: \(\pi_\theta(y|x)=\prod_{i=1}^{len(y)}p(y_i|x,y_{\leq i}).\) 因此,由于$p(y_i|x,y_{\leq i}) \in [0,1]$,使得$\pi_\theta(y|x)$的数值大小高度依赖数据所包含的token个数,从而导致DPO的优化过程具有显著的长度敏感性,可以总结为:
- 当数据对中Chosen更长,而Rejected更短时,相较于非偏好方向,模型在偏好方向拥有更大的梯度值。
- 当数据对中Chosen更短,而Rejected更长时,相较于非偏好方向,模型在偏好方向拥有更小的梯度值。
另外,文中还对两个优化方向的实际数值与其预测概率的关系进行分析,如下图所示,沿偏好方向的梯度数值关于$\pi_{\theta}(y_w|x)$单调递减,关于$\pi_{\theta}(y_l|x)$单调递增;沿非偏好方向的梯度数值关于$\pi_{\theta}(y_w|x)$与$\pi_{\theta}(y_l|x)$均单调递减,同样可以反映出DPO算法的优化过程具有显著的长度敏感性。
3 LD-DPO
针对DPO的长度敏感特性,本文设计了基于DPO的长度脱敏优化算法——LD-DPO,通过对预测概率的重新建模来减少数据长度对优化方向梯度的影响,从而实现脱敏。具体来说,论文作者定义偏好数据对的公共长度为$l_p=min{len(y_w),len(y_l)}$,预测概率$\pi(y|x)$可以表示为: \(\pi(y|x)=\prod_{i=1}^{l_p}p(y_i|x,y_{\leq i})\prod_{i=l_p+1}^{l}p(y_i|x,y_{\leq i}),\) 当数据过长时,上式中的$\prod_{i=l_p+1}^{l}p(y_i|x,y_{\leq i})$部分导致$\pi(y|x)$迅速衰减,从而使得DPO算法具有长度敏感性。依据上述分析,文章对该部分进行重新建模,将长度带来的偏好从人类真实偏好中解耦,即:
\[\prod_{i=l_{p}+1}^{l}\underbrace{p^{\alpha}(y_i|x,y_{\leq i})}_{\text{human-like}}\underbrace{p^{1-\alpha}(y_i|x,y_{\leq i})}_{\text{verbosity}}.\]进一步将冗长偏好部分从预测概率中消除并通过简化,得到LD-DPO的最终预测概率计算式:
\(\hat{\pi}(y|x)=\prod_{i=1}^{l}p^{\alpha}(y_i|x,y_{\leq i})\prod_{i=1}^{l_p}p^{1-\alpha}(y_i|x,y_{\leq i}).\)
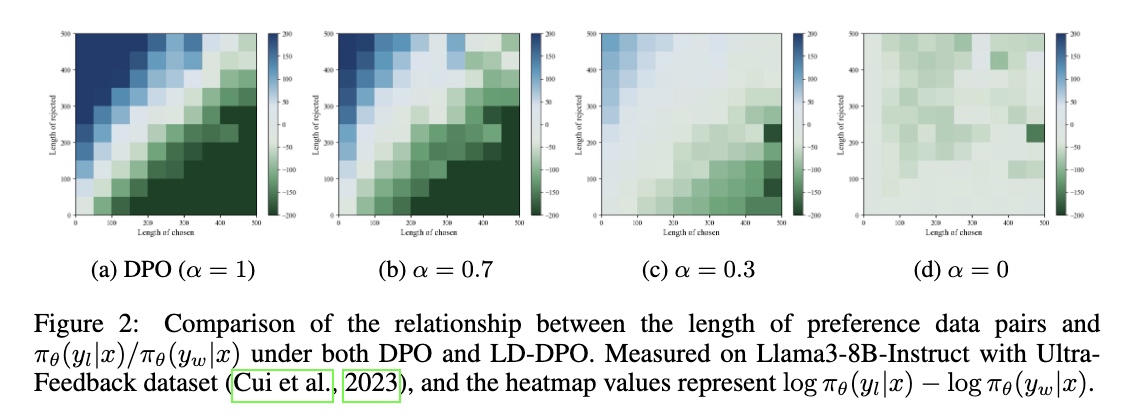
如下图所示,本文对实际偏好训练过程中的$\pi_{\theta}(y_l|x)/\pi_{\theta}(y_w|x)$进行统计分析,可以发现DPO算法中该数值与数据长度存在显著关联,在LD-DPO算法中,随着超参数$\alpha$的减小,这一关联正在逐渐减弱,当$\alpha=0$时意味着优化过程只考虑偏好数据对中的公共长度部分,此时数据长度已经不再作为变量。
4 主要实验
4-1 实验设置
本文选择三类模型系列Llama2-13B、Llama3-8B、Qwen2-7B中的两种设置(Base、Instruct)进行实验;偏好优化阶段选取UltraFeedback数据集;评测集主要选取MT-Bench、AlpacaEval 2(其余评测集指标见文章附录);对比的基线方法为近期相关的偏好优化工作:DPO、R-DPO、SimPO、WPO及SamPO。
4-2 实验结果
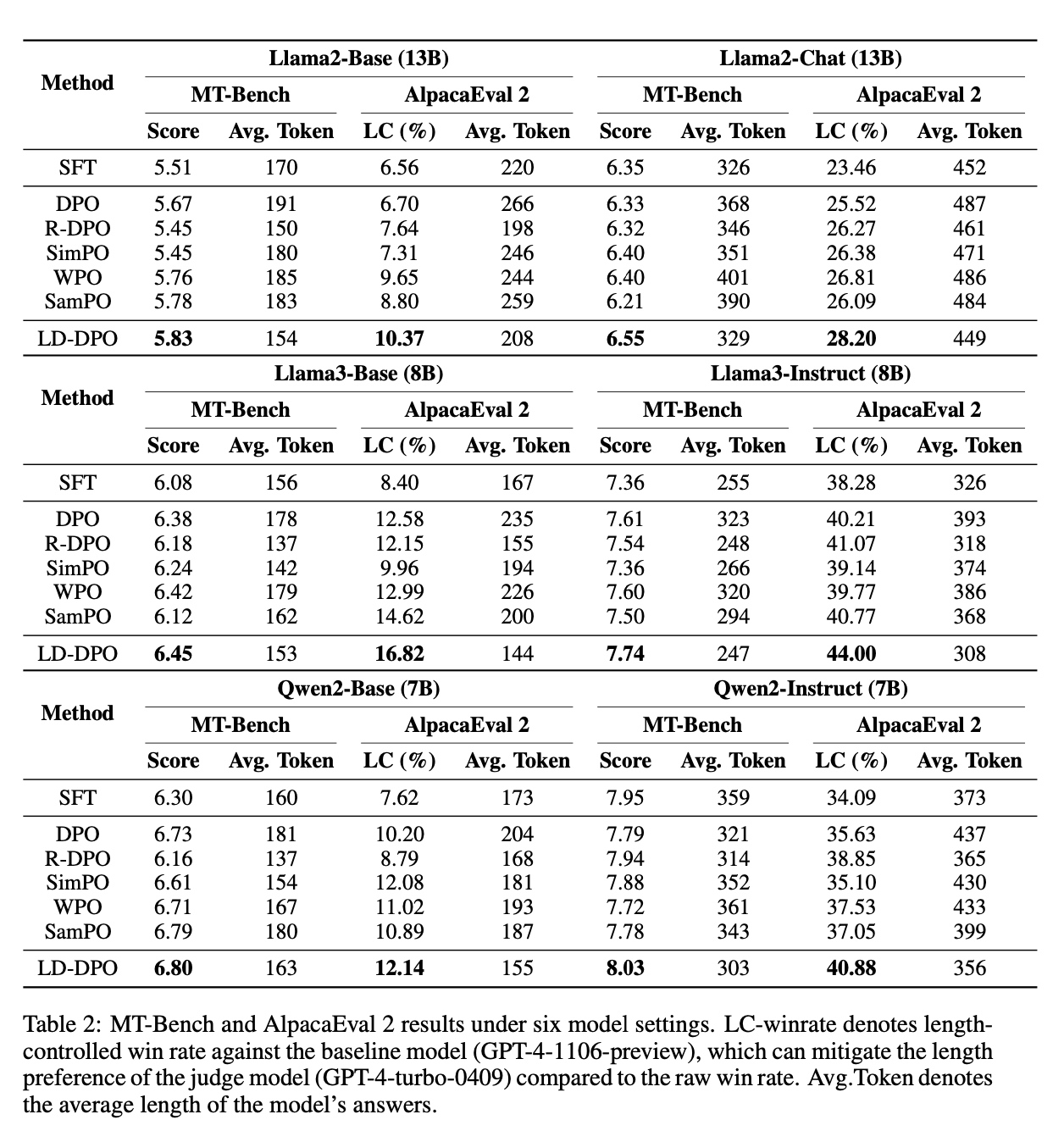
根据下表,可以得到结论:在六种不同设置下,LD-DPO在MT-Bench及AlpacaEval 2上的性能表现均超越其他基线方法,并且相较于标准的DPO算法,LD-DPO算法的平均回复长度下降10%~40%,说明模型通过LD-DPO算法优化,倾向于输出简洁的高质量回复,更好地实现与人类真实偏好的对齐。
4-3 不同模型的长度敏感性分析
如下图所示,文章对不同能力模型的训练过程进一步分析,发现在DPO训练过程中,长度敏感性与模型能力呈负相关。进一步,文章定义长度敏感系数$\gamma=1-\alpha_s$,其中$\alpha_s$为LD-DPO算法的最优超参,提供了一个偏好优化过程的评估维度。
4-4 消融实验
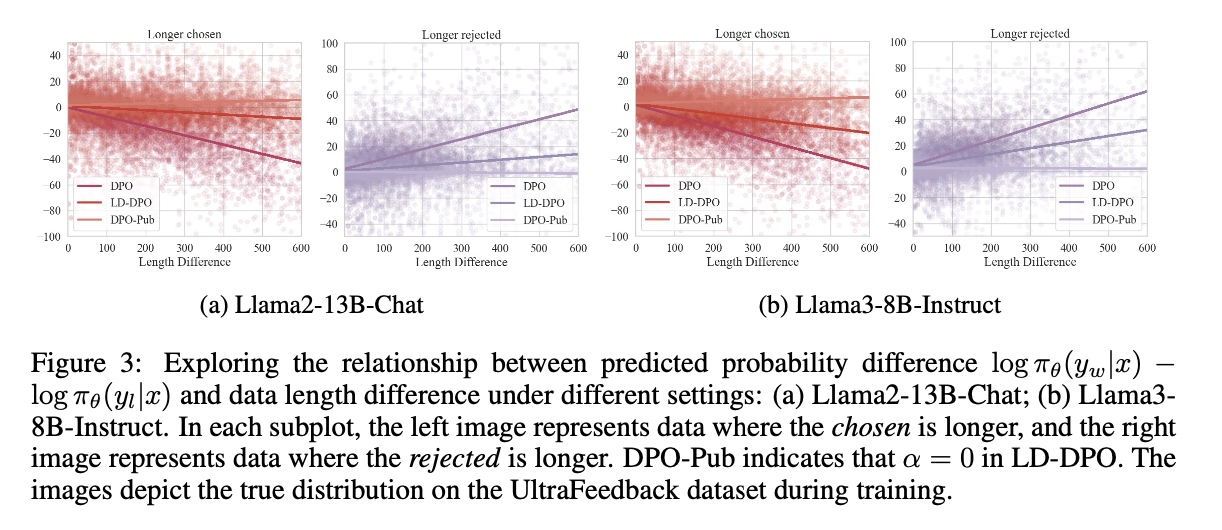
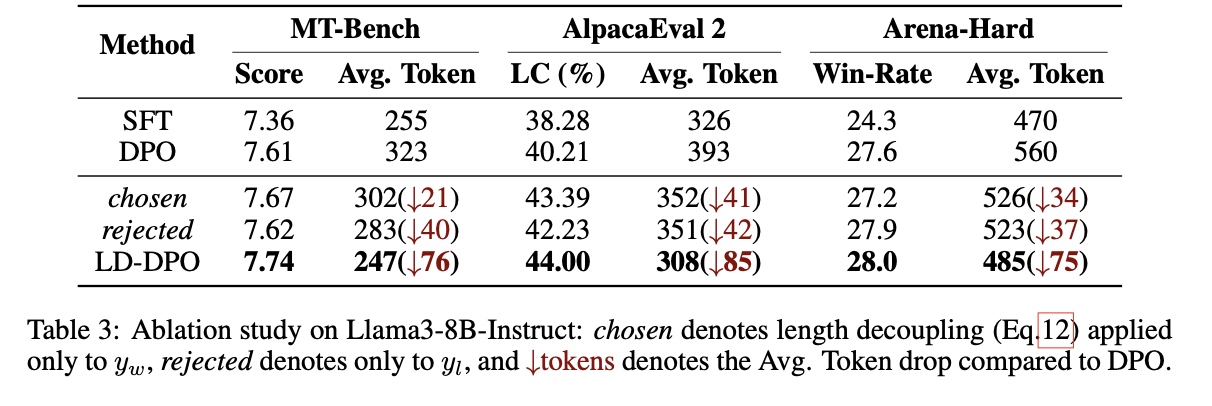
文章中进行了长度解耦目标的消融实验,如下图所示,分别针对偏好数据(Chosen)和非偏好数据(Rejected)的预测概率进行长度解耦,得出结论:不论是Chosen还是Rejected,都应进行预测概率的重新建模,否则DPO算法的长度敏感性均会导致输出长度的过优化。
4-5 超参分析实验
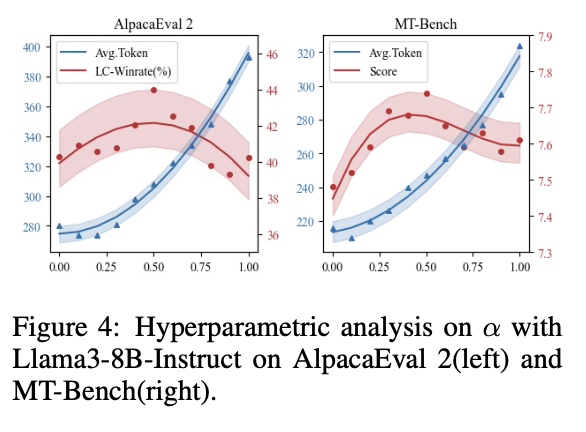
文章在Llama3-8B-Instruct模型上进行了超参分析实验,如下图所示,随着超参数$\alpha$数值减小,产出模型在AlpacaEval 2和MT-Bench上的平均回复长度持续衰减后保持稳定,其在AlpacaEval 2上的LC-Winrate(Length Control Winrate)以及在MT-Bench上的平均得分先增后减,并在$\alpha=0.5$时达到性能最优。当$\alpha$取值过大时,偏好优化过程受长度敏感性的影响,导致回复冗长且质量较低;当$\alpha$取值过小时,会损失部分人类真实偏好信息,导致优化性能不佳,应当根据模型基础能力及偏好学习中的长度敏感性确定合适的超参数(文章提供了实验所用模型的推荐参数选择)。
5 总结
本文针对DPO算法会导致模型生成冗长响应这一业界公认现象,第一次提出DPO算法具有长度敏感性,并基于DPO的优化损失函数进行理论与实验分析。在此基础上,文章提出LD-DPO算法,通过对模型预测概率的重新建模来缓解数据长度对其造成的影响,从而实现对DPO算法的长度脱敏。实验部分,文章使用Llama2-13B、Llama3-8B、Qwen2-7B的两种不同设置(Base、Instruct),在包括MT-Bench、AlpacaEval 2在内的多个主流评测集上进行验证,证明LD-DPO算法优于当前其他偏好优化算法,且相较于DPO算法可以有效降低产出模型的回复长度。最后,文章比较了不同能力模型的长度敏感性差异,为后续的偏好优化工作提供新视角。
参考
[1] Direct Preference Optimization: Your Language Model is Secretly a Reward Model
[2] Provably Robust DPO: Aligning Language Models with Noisy Feedback
[3] SimPO: Simple Preference Optimization with a Reference-Free Rewarda
[4] WPO: Enhancing RLHF with Weighted Preference Optimization
[5] Eliminating Biased Length Reliance of Direct Preference Optimization via Down-Sampled KL Divergence