
Corex:通过多模型协作增强推理能力 (COLM 2024)

论文题目:Corex: Pushing the Boundaries of Complex Reasoning through Multi-Model Collaboration
论文地址:https://openreview.net/forum?id=7BCmIWVT0V
项目地址:https://github.com/QiushiSun/Corex
1 引言
大语言模型(LLMs)通过超大规模的训练数据展示了强大的语言理解能力,并成功推动了许多NLP任务的性能飞跃。然而,尽管这些大模型在执行典型任务时表现卓越,但它们在复杂推理任务中的表现仍受到诸多限制,如推理链(思维链)的累积错误以及缺乏灵活性。
本文提出了一种名为 Corex 的框架,利用Multi-Model Collaboration(多模型协作),突破单一模型的推理瓶颈,通过三种解推理问题的模式(Discuss、Review 和 Retrieve)有效提高了推理的准确性,事实性(Factuality)和忠实性(Faithfulness)。实验结果表明,Corex 在多个基准数据集上显著优于现有的baselines的方法。
2 背景与动机
单模型解推理任务的局限性。在Chain-of-Thought (CoT) prompting出现后,通过生成一系列中间步骤引导模型得出最终答案成为了解推理任务的主流,相比仅生成“答案”的提示策略表现更好。此后,研究者又提出了多种改进方法,如采样更多推理链或加入code来辅助推理(详见baselines)。
尽管这些方法在一定程度上都改进了推理性能,但仍然局限于LLMs是一个静态的”Black Box”,即模型完全依赖其Internal Representation(内部表征)生成答案,这种方式容易导致不可靠的结果。此外,单纯依赖解码策略和curated prompting也无法完全解决复杂推理任务。
其中典型的错误可以被总结为以下几类,即(1)模型计算错误(2)模型理解错误(3)代码生成错误

因此,本文提出了Corex,一个受人类启发的模型协作策略集合,通过多模型协作激发复杂任务的推理能力。为促进模型之间的协同作用,我们首先为不同的LLM Agents在推理过程中分配角色,随后设计了多种协作范式来解决问题。这种基于集体智能的方法旨在克服当前推理领域的主要挑战,如下图所示。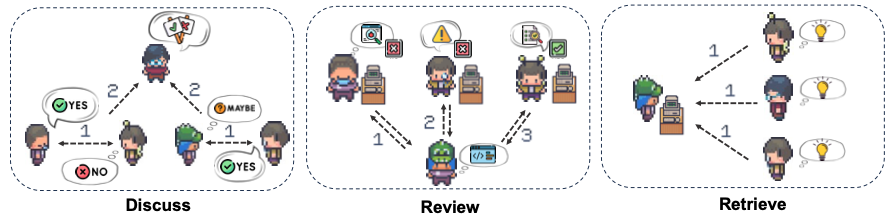
具体而言,Corex将若干个LLM配置为一组reasoning agents,并拥有如下多模型协作范式:
- Discuss 模式:通过模型间的群组讨论,有效提高推理链的事实性(factuality)和多样性(Diversity),减少累计错误和幻觉。
- Review 模式:模型间对推理链或生成的代码进行review,以确保生成内容的正确性,同时支持潜在的改进。
- Retrieve 模式:通过对多个推理链进行评分和排序,帮助模型从中选择最可信(faithful)的答案,提高最终结果的可靠性。
3 Corex:多模型协作推理
3-1 基本设定
假设有一组基于LLM agents $A_1,A_2,…,A_n$ 参与多模型协作。在面对一个问题 $q$ 时,每个agent $A_i$ 会生成相应的推理链 $c_i$ 和预测结果 $p_i$。这些推理链和预测结果将作为协作过程的基础,分别用于不同模式的任务分工和协作优化。以下为Corex中的三种协作模式解读:
3-2 Discuss
模型间的信息交换能够显著提升推理的准确性。在 Discuss 模式中,Corex 将基于LLM的智能体随机分为两组并指定一个Judge模型 $A_j $ 负责最终评估。讨论过程由多个轮次组成,最多进行 T 轮交互。
在每轮交互 $t (t=1, 2, \dots, T)$ 中,各组agents通过迭代讨论不断优化推理链 $c_i^t$ 和预测结果 $p_i^t$。这种动态交互机制允许模型针对问题 $q$ 持续调整和改进观点。

Discuss mode的工作流程如下:
- 组内优化:每轮结束时,蓝队和绿队分别提交优化后的预测结果 $p_{\text{blue}}^t$ 和 $p_{\text{green}}^t$。
- 结果一致性检查:如果两组在整个过程中始终保持一致(即 $p_{\text{blue}}^t = p_{\text{green}}^t$ ),讨论顺利结束,直接得出结论。
- Judge评估:若两组预测结果存在分歧,每轮的所有输出(包括推理链和预测结果)都会交由裁判 A_j 审查。裁判通过决策过程 h,综合评估蓝队和绿队在各轮讨论中的推理链 $c_{\text{blue}}^t$、$c_{\text{green}}^t$ 以及预测结果 $p_{\text{blue}}^t$、$p_{\text{green}}^t$,最终作出决策。
先前的方法往往依赖一组模型直接进行相互Debate,这容易导致(1)强模型主导了整个交互的过程,覆盖了其他模型能为解决问题所作出的贡献(2)错误的consensus在交互过程中被传播;而Corex的Discuss则通过分组 + Judge的方式,避免/缓解了上述问题。
3-3 Review
在推理任务中,CoT和PAL是两种行之有效的方法,但它们各有优劣:CoT方法以自然语言为基础,具有通用性和解释清晰的优势,但存在以下局限:
- 累积误差:推理链中的错误会逐步放大并影响最终结果。
- 输出瓶颈:文本质量无法通过进一步优化提示词显著提升。
PAL方法通过程序生成保证了计算的准确性,但也面临以下问题:
- 问题误解:LLMs可能误解问题,生成技术上正确但逻辑上错误的程序。
- 代码错误:生成的代码可能存在问题,例如引用未定义变量或“除零”等错误。
为了解决这些问题,Corex引入了Review模式,利用多智能体协作对推理链和代码进行逐步review与 optimization。这一模式受LLMs互评机制以及软件工程中协作编码实践的启发。除了使用NL推理链,还可以结合代码生成来辅助推理。
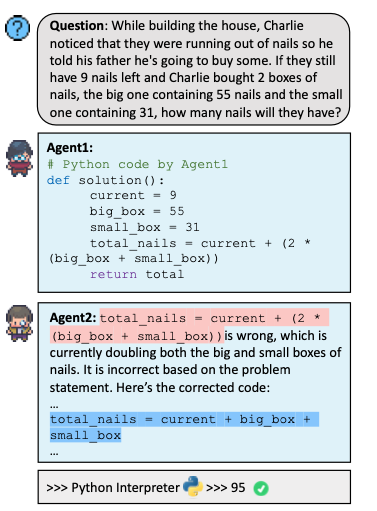
Review mode的工作流程如下:
初始生成:随机选定一个Agent A_p 作为主模型,负责对问题 $q$ 构建初始推理链、预测答案和生成代码(如果需要)。其初始解决方案集合表示为:$S_{p}^{(0)} = {a_p, c_p, m_p}$ 其中,$a_p$、$c_p$、$m_p$ 分别表示答案、推理链和代码。
逐轮review:其他Agents依次作为审查者,对主模型 A_p 或之前的审查者修改后的NL推理链和生成的代码进行严格审查。每个审查者基于前一轮的反馈和结果提出改进,推动解决方案的逐步优化。
Review过程可形式化表示为:$S_{p}^{(i+1)} = R_i(S_{p}^{(i)}, F_i)$,其中,$R_i$ 表示第 $i$ 轮的审查结果,$F_i$ 是该轮反馈,$S_{p}^{(i+1)}$ 是改进后的解决方案集合。
最终输出:审查完成后,采用最后一轮的解决方案集合 $S_{p}^{(n-1)}$。
- 对于推理任务,最终答案为 $a_{p}^{(n-1)}$。
- 对于涉及代码生成的任务,执行修订后的代码版本 $m_{p}^{(n-1)}$ 来得出最终结果。
此模式中,每轮审查都基于前一轮反馈,逐步改进对一个推理问题的解决方案。通过多轮交互修复推理链和代码中的累积错误。
3-4 Retrieve
Retrieve模式专注于通过模型间的协作,识别推理过程中最可信的答案。相比于投票机制,Retrieve模式有效解决了以下两个主要问题:
- 错误干扰:正确答案可能被大量错误答案掩盖,从而影响最终结果。
- 计算成本高:尽管多数投票机制在性能上有所提升,但其计算成本随着采样推理链数量的增加而增长,且最终会达到性能的饱和点。
这些问题的根源在于多数投票方法的局限性:它们只关注预测结果,而忽视了推理链的可信度。为了解决这些不足,Retrieve模式被设计为一种全新的方法,用于评估答案是否能够被推理过程中的内容(解释)支持。

Retrieve mode的工作流程如下:
Candidates生成
- 针对查询 q,随机选定一个Agent $A_r$ 作为retriever,其余Agents ${A_1, A_2, \ldots, A_{n-1}}$ 独立解决问题。
- 每个Agent生成其推理链 $c_i$ 和对应的预测结果 $p_i$,构成候选池 $\mathcal{P} = {(c_i, p_i)}_{i=1}^{n-1}$。
可信度评估
- Retriever A_r 对候选池中的每组推理链-预测结果对 $(c_i, p_i)$ 进行审查,评估推理链 $c_i$ 与预测结果 $p_i$ 之间的可信度。
- 每个candidate分配一个范围在 [0,1] 的confidence $s_i$,表示为:
$s_i = f_r(c_i, p_i)$
其中,$f_r$ 表示retriever的评估过程。
答案选择:从候选池中选择可信度最高的推理链-预测对 $(c^, p^)$,作为问题 $q$ 的最终答案。
Retrieve模式的特点与优势
- 推理链与答案的高一致性:Retrieve模式确保选出的答案能够与推理链内容高度一致,解决了多数投票中错误答案占优的问题。
- 高效且独立:不同于依赖序列对数概率的文本质量评估方法,Retrieve模式完全基于模型间的交互,无需依赖额外的外部参考资源。
4 实验
4-1 实验设置
实验主要依托GPT-3.5-Turbo模型(以及分析实验中的GPT-4和Claude),在大量的主流benchmarks上进行了测试。
4-2 Baselines
我们将Corex与几种广泛使用的强基线方法进行了比较:
- Chain-of-Thought prompting (CoT) :经典baseline方法
- Self-Consistency (CoT-SC) :采样多个推理链的结果,选择一致性最高的答案作为最终结果
- Complexity-based consistency (ComplexCoT) :从具有更高推理复杂性的候选答案中选择多数结果
- Program-aided language model (PAL/PoT) :利用LLMs进行代码生成作为中间推理步骤,并将计算任务offload到Python解释器执行,从而减少计算误差。
4-3 主实验
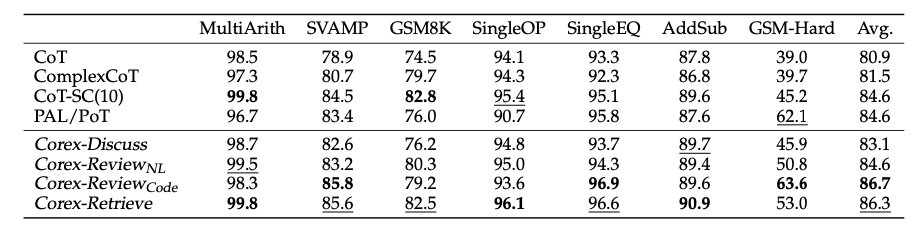
Math Reasoning. 下表展示了Corex在不同难度math reasoning任务上的表现。总体来看,Corex相比大多数baselines取得了显著的性能提升。即使只使用5个reasoning agents,Corex的表现也优于使用10条推理链的CoT-SC方法。此外,Corex的任务无关性使其能通过Reviewing + Code Generation来应对像GSM-Hard这样的高度复杂计算任务。而对于较低复杂度的问题,Retrieve模式能够选择出优于多数投票机制的答案。
Commonsense Reasoning. 下表展示了Corex在commonsense / factual reasoning任务中的表现。由于这类任务的性质无法直接转换为计算任务,Review模式在此类任务中仅使用NL作为推理链。从实验中可以看到,不同模式的协作都对性能提升有明显贡献。
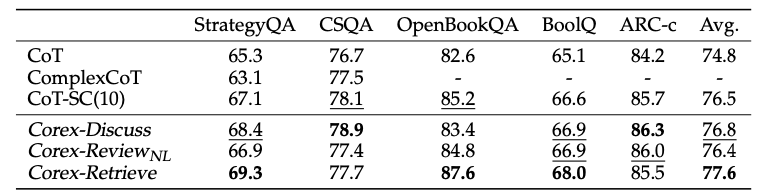
相比于ComplexCoT,Corex可以在StrategyQA任务上获得6%的提升。方法层面来看,Discuss mode带来的提升最大,也侧面反映了模型交互可以减少unfactual信息的传递。
Symbolic Reasoning. 以下展示了Corex在Symbolic reasoning任务中的表现。实验结果表明,多模型协作在Big-Bench任务中显著优于大多数现有baselines。需要注意的是:(1) CoT-SC方法在处理Repeat Copy任务时难以确保一致的输出,而通过整合code generation来协作,Corex成功达到了更高的准确率;(2) 在Counting任务中,相较于多数投票,Review mode和Retrieve mode能够做出更为明智的答案选择。
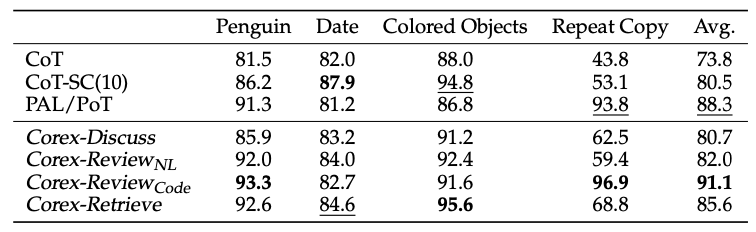
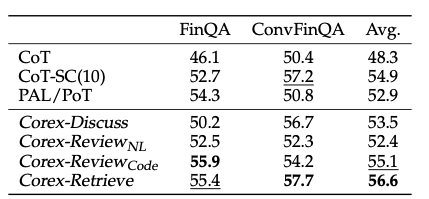
Table Reasoning. 最后,Corex在FinQA和ConvFinQA这两个半结构化推理(表格推理)任务上的表现。可以观察到,这两个任务需要同时理解异构信息和执行复杂计算,在此类任务中,CoT-SC等方法的性能提升有限。然而,Corex通过多种协作模式显著提高了性能。
此外,本文还在后续分析中补充了 TAT-QA 的性能,详见原文。总体来说,在18个benchmarks的广泛实验中,Corex的Discuss mode在处理基于事实知识的任务时表现良好;对于复杂的数学推理和计数任务,Review模式(结合code generation)能够有效减少推理链中的错误并修复不正确的代码。而在一般场景下,Retrieve mode持续地对性能提升起到了积极作用。本文的附录中还添加了更多(1)基于开源模型的实验(2)错误类型分析等。
5 分析实验
本文还进行了大量分析实验,来探讨多模型合作方法中(1)Corex内部的模型行为(2)与其他方法的比较(3)使用不同LLM作为backbones进行协作。
5-1 Corex策略分析
Discuss轮次分析. 我们首先研究了Corex的Discuss mode在五个任务中的交互轮次分布情况,如下图7所示。对于大多数问题,每个sub-group能够迅速达成一致。然而,对于难以快速达成共识的问题,Corex允许LLMs进行更深入的讨论。例如ConvFinQA任务中,有超过10%的问题需要超过3轮交互才能达成共识。尽管仅有一小部分问题需要较多轮次的讨论,但这种深入的互动过程为Judge的决策提供了良好的依据。
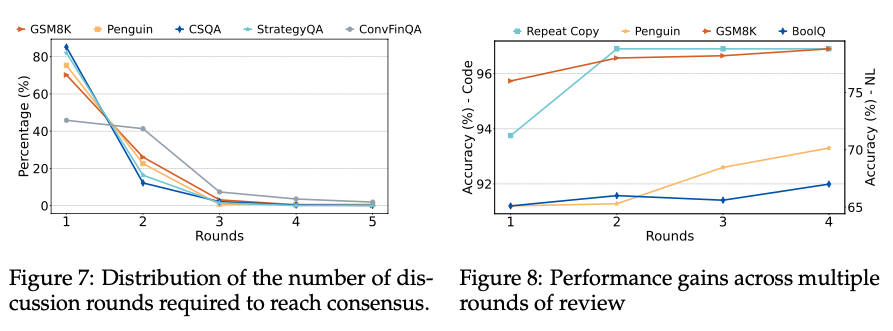
Review性能增益分析. 我们还分析了Review mode中每轮审查对特定任务性能提升的贡献。如图8所示,我们对Repeat Copy和GSM8K任务(Review + Code模式)以及BoolQ和Penguin任务(Review + NL模式)进行了分析。结果表明,每轮审查通常都会带来性能的逐步提升。然而,在某些情况下,性能可能会出现小幅波动。这种现象表明,尽管整体上Review模式能够显著改进任务表现,但具体的增益效果可能受任务特性和模型生成的中间输出质量的影响。
5-2 多模型协作方法比较与融合
与其他协作推理方法的比较. 为了对比当前在推理任务中使用多模型协作的方法(详见论文第2节),我们选择了两种具有代表性的研究进行性能比较:
- Multi-Agent Debate (MAD) :多个模型分别表达自己的观点,由一个Judge管理辩论过程并最终决定解决方案。
- Exchange of Thought (EoT) :一种基于网络拓扑结构的跨模型通信策略来增强推理能力的方法。
如表5所示,Corex在不同模式下的表现始终优于这两种创新性方法。这表明,Corex的协作框架不仅能够整合多模型的优势,还可以在性能和效率上超越现有的协作方法。
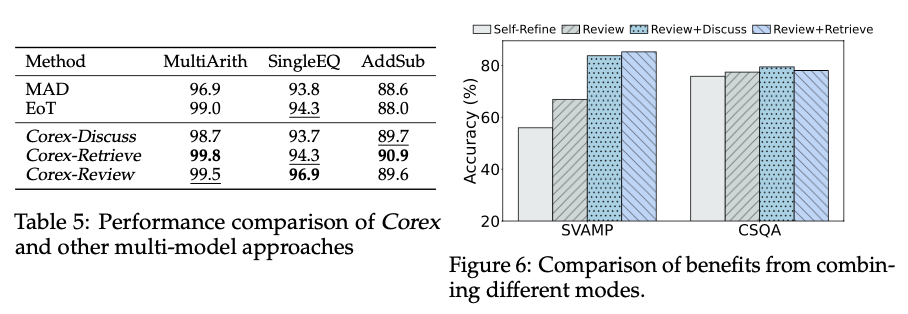
各策略间的协同效应. 在主要实验中,为了公平对比,我们分别独立评估了Corex的每种模式。接下来,我们探讨将不同模式结合使用是否能够进一步提升性能。我们采用了一种相对简单且计算成本适中的方法:在其他模式协作后应用Review模式,同时将Self-Refine 作为baseline,用于验证协作所带来的额外增益。
如图6所示,我们发现以下几点:
- 任何形式的协作都优于单纯的Self-Refine,表明多模型协作在推理任务中具有明显优势。
- 结合不同Corex模式的协作通常能进一步提升性能,尤其是在处理LLMs的弱项(如数值计算任务)时,这种协作效果尤为显著。
以上结果表明,各模式间的协同作用可以更有效地克服单一模式的局限性,为复杂任务的解决提供更好的支持。
5-3 不同LLMs协作
不同LLMs作为Judge时的性能变化. Corex的reasoning agents可以基于多种不同的LLM。在本部分中,我们先讨论在Discuss mode中使用不同LLMs作为Judge时的性能表现。如下图9所示,我们使用GPT-3.5-Turbo作为candidates,并分析了不同模型作为Judge对任务表现的影响。观察表明,Judge的能力与任务性能正相关,尤其是在任务复杂度较高的情况下更为明显。这可以归因于裁判在Corex中的关键角色——不仅需要理解任务问题,还需要评估双方的推理过程并作出决策。
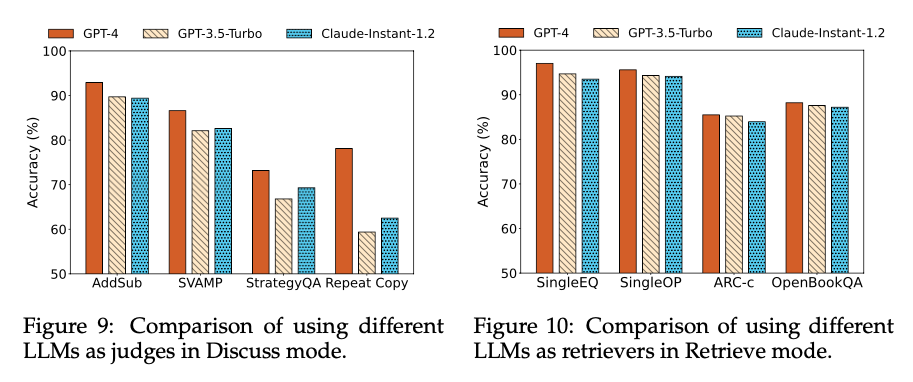
使用不同LLMs作为Retriever的影响. 在Retrieve mode中,retriever的角色可以由不同的LLM担任。我们探讨了选择不同LLM作为retriever对性能的影响(见图10)。与Discuss mode不同,分析结果显示retriever的模型能力对性能的影响较小。由于性能上限由候选答案的质量决定,不同LLMs作为retriever在任务(如ARC-c)上的表现差异甚微。值得注意的是,我们的研究表明,即使不使用特别强大的模型作为retriever,也能取得令人满意的结果。
5-4 效费比分析
最后,本文对 Corex vs 不同CoT模式的效费比进行了分析。
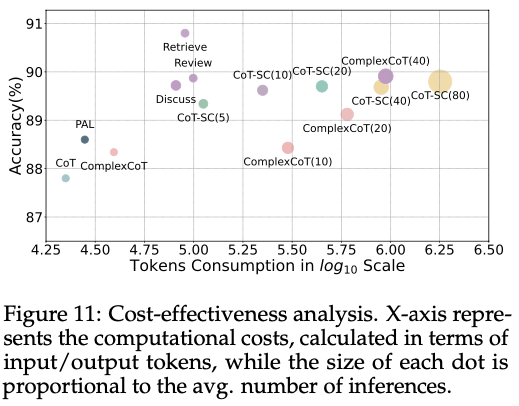
从上图所示的AddSub任务分析可以看出,Corex的三种协作模式在性能上始终能够匹敌或超越其他强baselisne。更为重要的是,与使用多数投票机制的方法相比,Corex的计算成本大幅降低。Corex在实现相同性能的情况下,其资源消耗仅为其他策略的5%-10%。
除了上述分析实验外,原文中还提供了更多对比和分析实验,并细究了推理问题的错误原因等,为后续研究提供了许多insights。
6 结论
作为Multi Agent的早期工作,Corex为基于LLMs的智能体生态系统提供了初步探索。通过激发LLMs之间的协同作用,Corex能够通过多种协作模式提升各项推理性能。它还证明了(1)对于不同类型的推理问题,多模型协同工作比传统单模型推理/多推理链独立推理能有更好的效果。(2)多模型推理可以通过更少的计算成本达到采样大量推理链才能达到的任务性能。(3)Corex的任务无关性使得其具有潜力被adapt到新的任务和场景上。我们希望这项工作能为复杂推理和集体智能提供新的视角和发展方向。