
黑箱优化:语言模型即服务
[论文导读] Black-Box Tuning for Language-Model-as-a-Service
最近在参与一个算法调优竞赛,学习了不少关于小样本学习、Prompt Learning以及模型优化方面的知识。在文献调研过程中阅读了一篇提出了一种大规模语言模型落地的算法(不计算模型梯度)的文章:Black-Box Tuning for Language-Model-as-a-Service(ICML 2022),文章来自FudanNLP,本篇博客记录一下其中的要点以及我个人对问题的理解。
Background
预训练语言模型(简称PTM)越来越大了,让它们能落地被实际的业务应用越发困难,而且,对于一些大型的商用模型(比如Open AI的GPT-3),它们并不开源,使用者也很难与模型本身交互。回顾一下,我们平时在使用小模型的时候往往是这么做的:
- 下载某个开源预训练模型的检查点/自己训练一个预训练模型
- 收集特定任务的标注数据
- Fine-tune预训练语言模型
- 上线推理
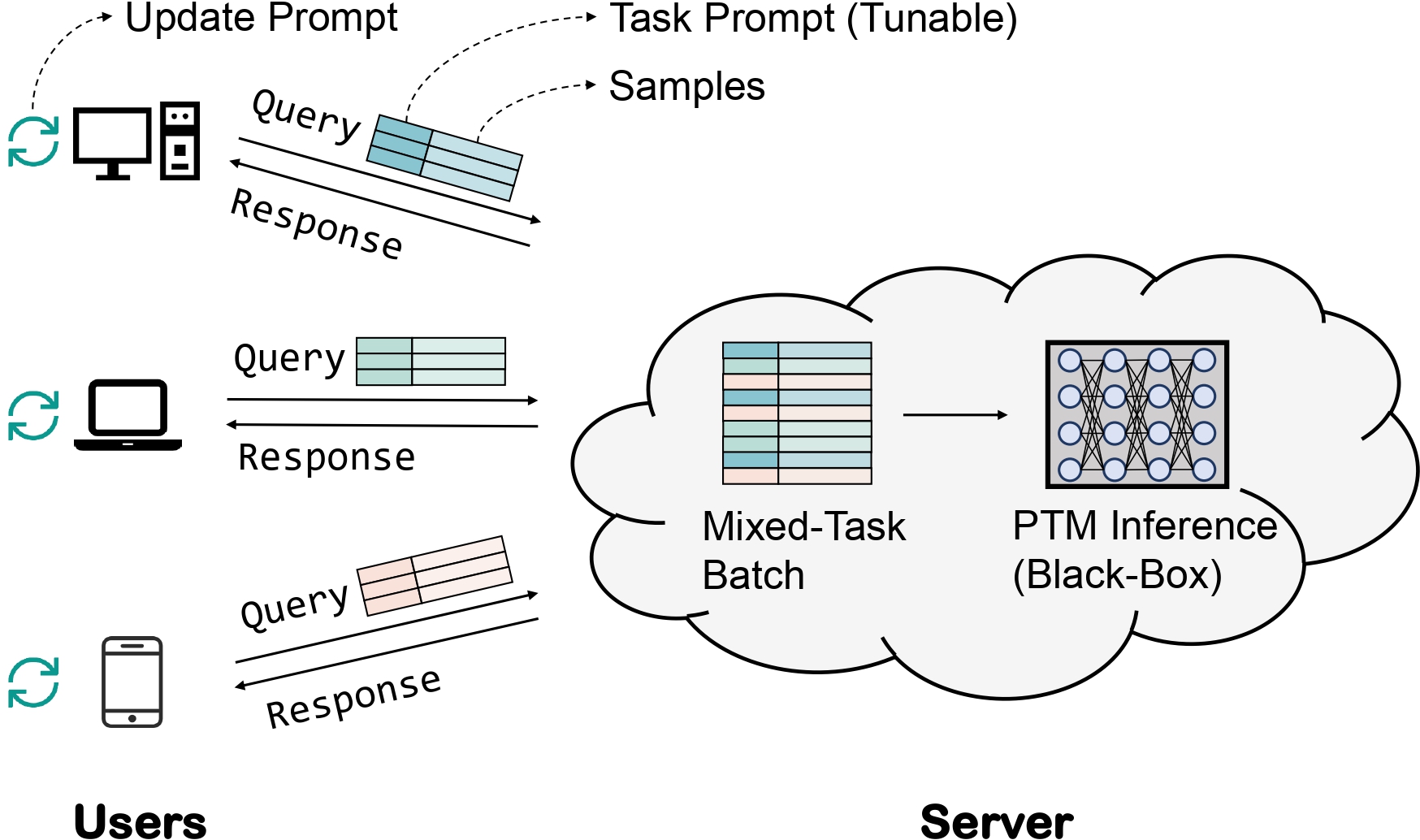
但是,随着模型变大,预训练和微调的成本都快速上升,再加上商用模型的限制,使用小模型的策略来玩大模型并不现实,比如GPT系列的模型,具体可参考:GPT-3 Demo。为了解决这些问题,作者提出了黑箱优化这个概念,用作者自己的话说就是:LMaaS是要把大模型当作发电厂,那自然不能给每家每户都派一个调电(调参)师傅过去,最好是每家每户能够自己把电器(任务)管理好,发电厂(大模型服务方)只需要确保供应电力(算力),这才是规模化的玩法。
In-Context Learning
GPT-3在他们的论文里给出的玩法就是in-context learning. 如下图所示,不需要进行反向传播,仅需要把少量标注样本放在输入文本的上下文中即可诱导GPT-3输出答案。
Prompt Learning
再往后,这种通过额外文本诱导模型提供正确答案(生成某些词,或是给出正确的分类结果等)发展成为如今大火的Prompt learning,将Downstream Tasks转化为(M)LM任务来直接用PTM解决,模型规模越大,其对语言建模的能力往往就越强,从(M)LM迁移到Downstream Tasks就越容易,那我们就可以用一个大规模通用PTM来解决各种下游任务了。
Language-Model-as-a-Service
概念补充:Parameter-Efficient tuning,即只微调少量参数,如Prompt Tuning,但是用户在服务端仍然需要调参。
个人认为,理解了下面这张图,就把黑箱优化这个新提出的概念理解了,在此处可将图右上角的“黑盒模型”视为一个不知道具体细节的函数f(x)

- Derivative-Free Optimizer:简称DFO,顾名思义就是一个不依赖模型给我梯度的优化器,实验中使用的是CMA(CMA Evolution Strategy)实现,全称是Covariance Matrix Adaptation Evolution Strategy,在PyPI中对应的是cma包。
- 本征向量 $z$:DFO优化的目标
- 随机矩阵 $A$:此处产生均匀分布(前人工作使用了正态分布),为DFO生成的向量增加随机/多样性
- 初始Prompt-Embedding $p_{0}$:从RoBERTa的词表中随机抽取一些单词,将其Embedding与DFO生成的向量进行“直和”,也就是每个位置对应相加。我个人认为这步的目的是让DFO生成的本征向量能尽可能靠近一个“靠谱”的词向量空间。
Reference:
- https://zhuanlan.zhihu.com/p/455915295