InstructGraph:以图为中心的大模型指令微调与偏好对齐 (ACL 2024)
 论文:InstructGraph: Boosting Large Language Models via Graph-centric Instruction Tuning and Preference Alignment
PDF:https://arxiv.org/pdf/2402.08785
Github:https://github.com/wjn1996/InstructGraph
Graph指令数据:https://huggingface.co/datasets/wjn1996/InstructGraph
论文:InstructGraph: Boosting Large Language Models via Graph-centric Instruction Tuning and Preference Alignment
PDF:https://arxiv.org/pdf/2402.08785
Github:https://github.com/wjn1996/InstructGraph
Graph指令数据:https://huggingface.co/datasets/wjn1996/InstructGraph
当大语言模型遇到图,会发生什么样的化学反应呢? 最近由华东师范大学(ECNU)和加州大学圣地亚哥分校(UC San Diego)联合提出了针对提升大模型在图推理和图生成能力的InstructGraph框架。该工作被ACL 2024接收为Findings长文。
1、LLM与Graph
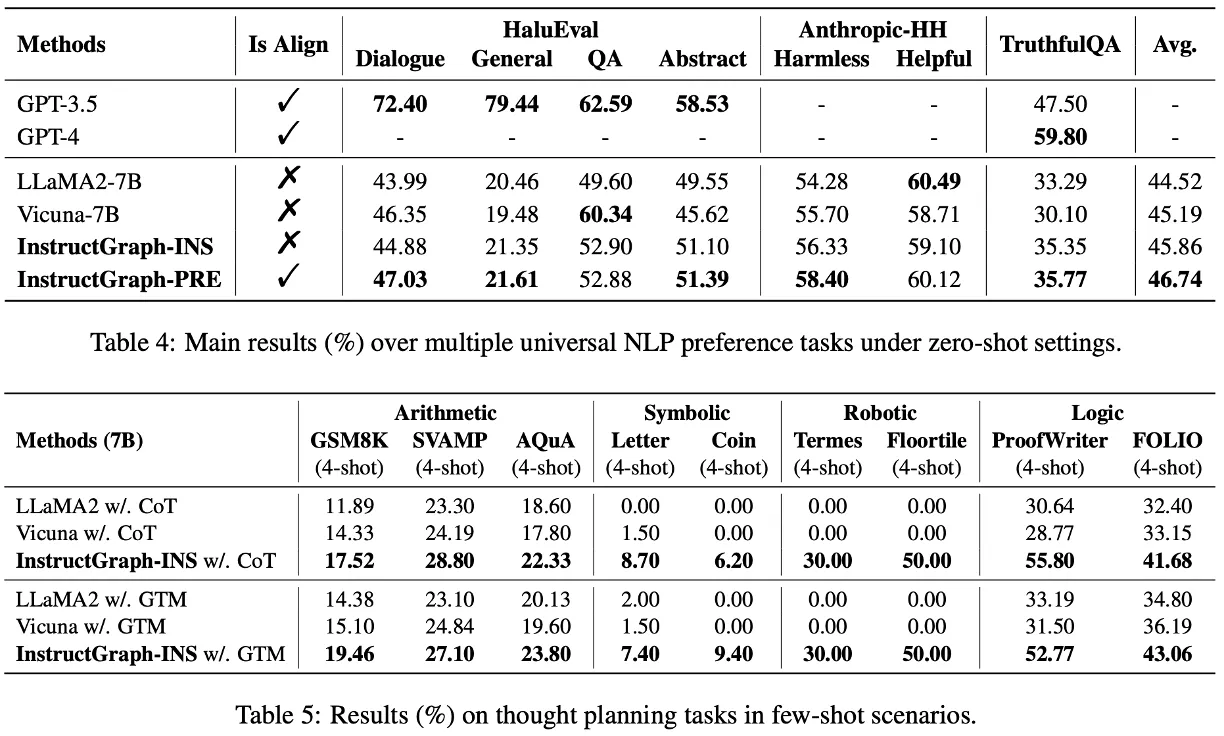
众所周知,大语言模型(Large Language Models,LLMs)是通过自回归式的Causal Language Modeling实现预训练,自然语言文本遵循着token-by-token的序列形式实现文本生成和推理。然而,图(Graph)则不是序列模式的数据,因此,如何让一个以序列为感知的大语言模型很好地理解一个图数据,是一大挑战。
最近一些工作尝试将图神经网络等模型集成在大模型基座上,使得模型能够按照原先的图学习模式感知图,并借助大模型的生成能力实现推理。 然而这类方法存在两个不足:
- 需要改变大模型的结构,使得模型很难自适应到任意的图,同时这类方法也无法有效地将图与文本很好的进行兼容;
- 只能够实现由图到文(Graph2Text)的转换,而无法实现图文之间的相互转换,例如Text2Graph。
 为了让大语言模型更好更有效地理解图或生成图,该工作提出InstructGraph框架,并考虑从三个方面来实现这一目的。
为了让大语言模型更好更有效地理解图或生成图,该工作提出InstructGraph框架,并考虑从三个方面来实现这一目的。
- Prompt Engineering:在输入模板层面上,如何将图与文实现比较好的对齐;
- Instruction-tuning:在监督微调时,如何让大模型能够很好地完成图推理与生成任务;
- Preference Optimization:在偏好对齐时,如何让那个大模型能够更准确地实现图的理解和生成,缓解幻觉问题。
2、提示工程:结构上对齐
文本是序列化的数据,图是结构化的数据,如何在输入层面上在不介入外部模型的条件下很自然地实现统一对齐呢?该工作想到了使用代码(Code)作为中间表示。
Code是一种天然的包含结构化信息的序列数据,现如今大语言模型之所以能够具备很强的推理性能,也得易于代码数据的引入。因此,如果将图用代码的形式来表达,那么就巧妙地实现了图文的统一结合,而对于大语言模型来说,处理图和处理代码相似,无需刻意地在输入感知上对图进行专门的表示学习。
为此提出Code-like Format Verbalizer,对于任意一个图,都可以转换为一个代码的结构模式。

基于这个Code-like Format形式,在做图到文(Graph2Text)时,大模型可以像理解代码一样理解图,然后通过文本生成完成回答;在做文到图(Text2Graph)时,大模型可以像写代码一样生成一个图。这一过程充分利用了大语言模型的代码理解和生成的能力。
3、图指令微调
对于GPT-4、GPT-4o等超大规模的模型,在提示工程的引导下大模型已然可以完成的很不错。但是对于较为小规模的模型,效果依然不行,那么就需要对小模型进行监督微调来赋予其图推理和生成的能力。
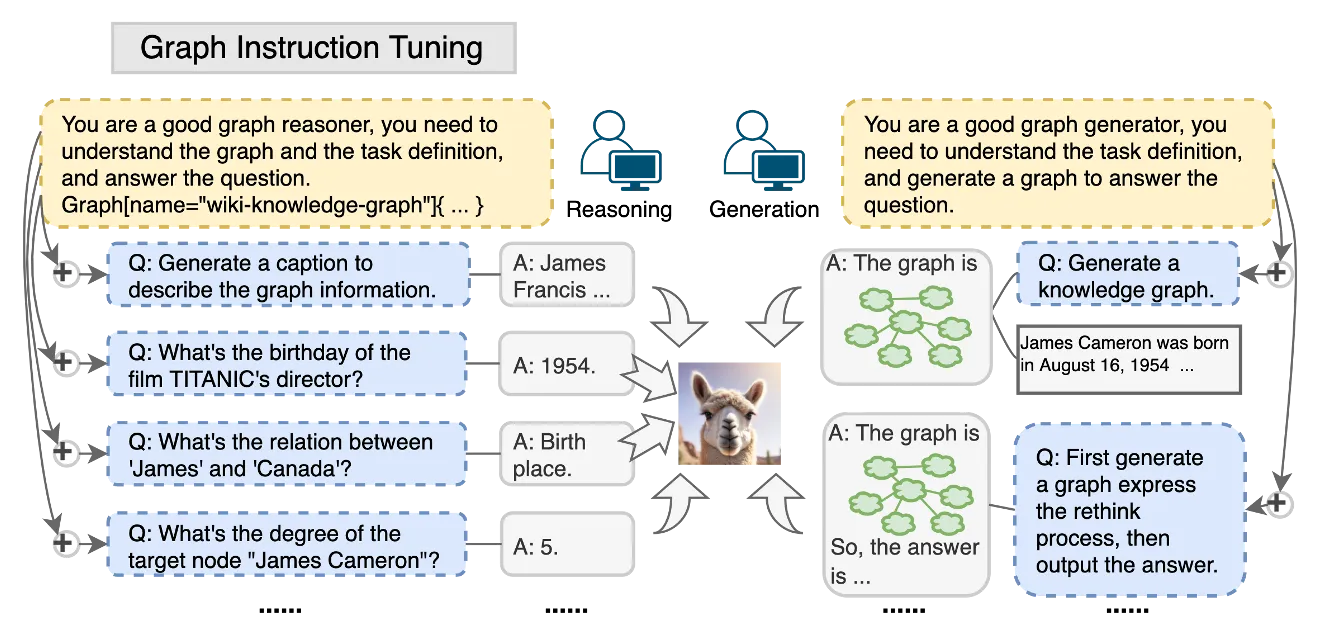 本文将图指令微调划分为两大范式:
本文将图指令微调划分为两大范式:
- 图推理:给定一个Query和一个Graph,回答问题;
- 图生成:给定一个Query,生成一个Graph。
为了达到这个目的,该工作收集了来自29个不同的针对图推理和生成的任务,并进行了数据预处理和指令构建,最终构建了大约1.6M语料。数据来自Wikipedia、Wikidata、DBPeidia、FIFA、Freebase、OGB、PubMed、Amazon、CiteSeerX、MoveLens、InstructUIE、InstructIE、ConceptNet、NLGraph、ArXiv、LastFM等。
 对这些图任务进行了更为细致的划分,划分为4个Group,如下所示:
对这些图任务进行了更为细致的划分,划分为4个Group,如下所示:
Graph Structure Modeling
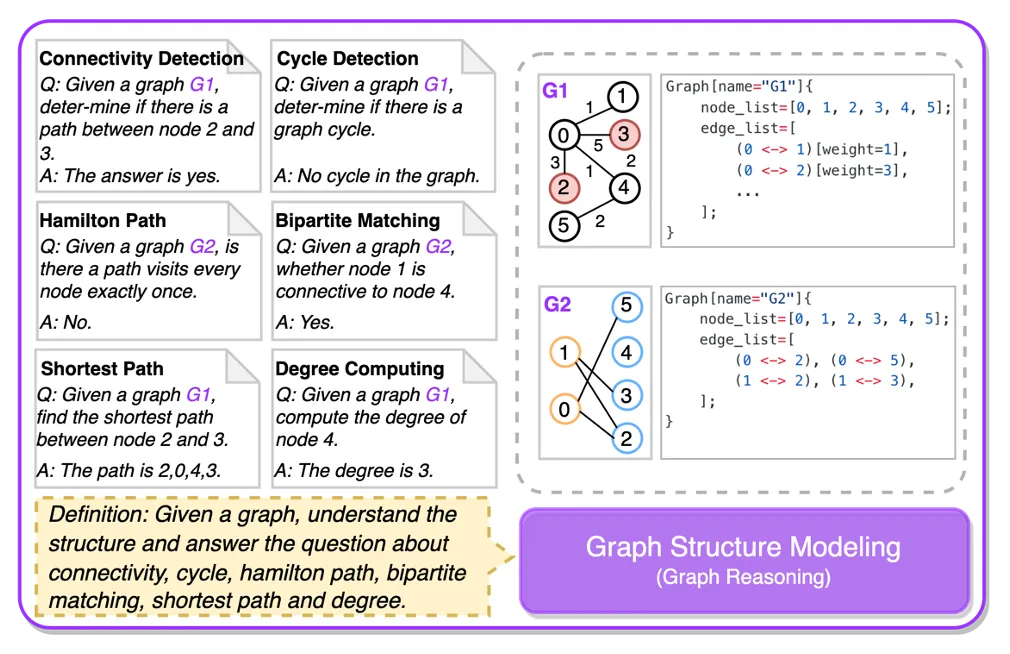 图结构建模任务旨在设计相应的指令,让LLM能够理解Graph结构相关的信息,包括图连通性、环、最短路径等信息。
先前工作NLGraph提出了8种与Graph结构相关的benchmark。这里挑选了前7个任务的训练集作为训练数据。
图结构建模任务旨在设计相应的指令,让LLM能够理解Graph结构相关的信息,包括图连通性、环、最短路径等信息。
先前工作NLGraph提出了8种与Graph结构相关的benchmark。这里挑选了前7个任务的训练集作为训练数据。
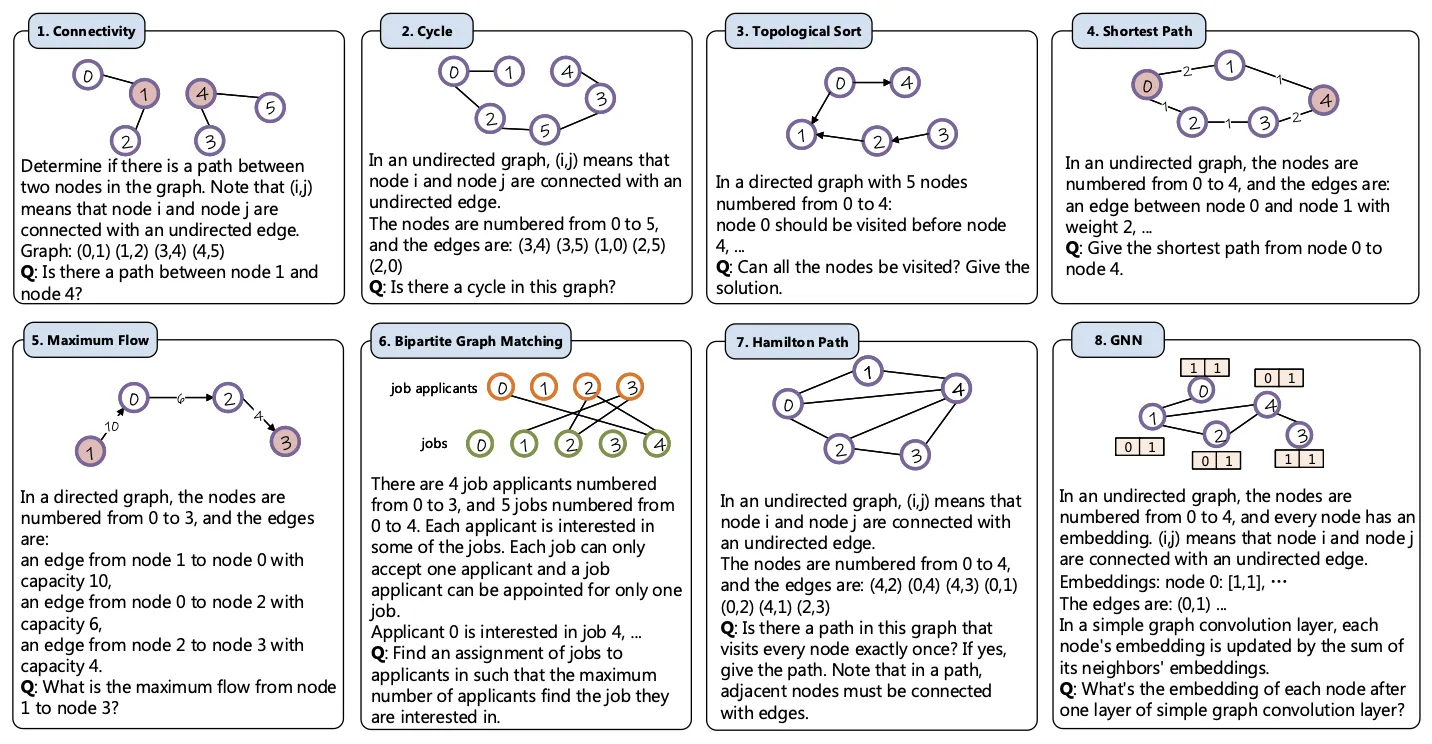 另外还增加了两个NLGraph中没有提及的任务:
另外还增加了两个NLGraph中没有提及的任务:
- Graph Degree Prediction:给定一个Graph,计算目标节点的度数,有向图则包括入度和出度。
- Graph Diameter:给定一个Graph,计算其直径。
Graph Language Modeling
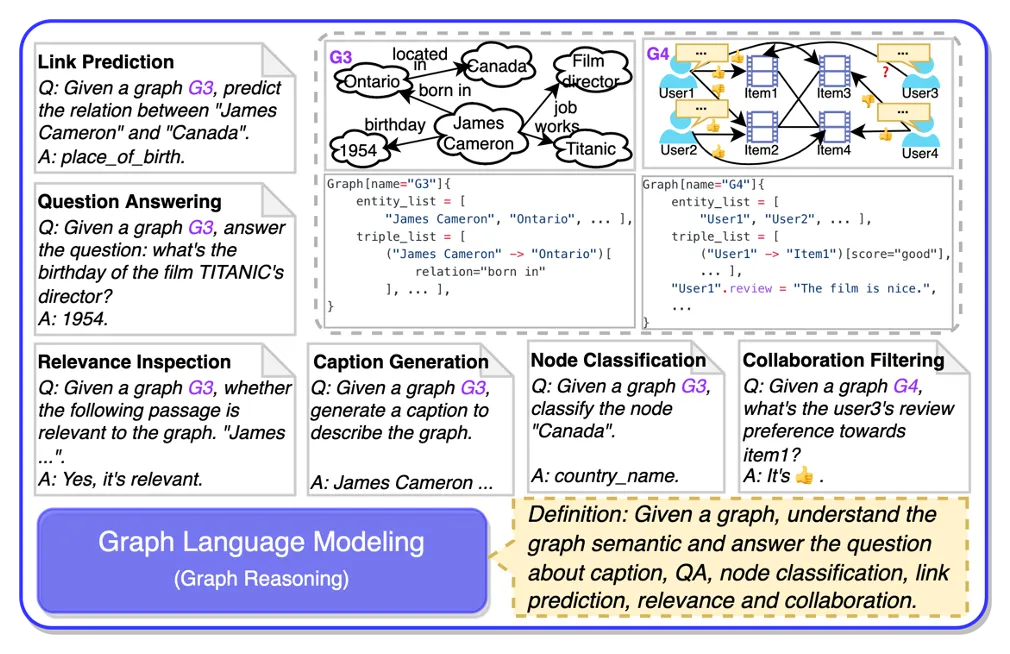 图语言建模旨在设计相应的指令,让大模型根据Graph来完成语言建模。这里包含若干类别的任务:
图语言建模旨在设计相应的指令,让大模型根据Graph来完成语言建模。这里包含若干类别的任务: - Caption Generation:基于Wikipedia和Wikidata,针对Wikidata给定的一个知识图谱,生成出Wikipedia中的文本描述;
- Question Answering:输入一个Graph,给定一个问题Query,回答相应的问题;
- Nodel Classification:输入一个Graph,对其中一个节点进行分类;
- Link Prediction:输入一个Graph,对其中两个节点的边类型进行预测;
- Relevance Inspection:输入一个Graph和一个文本描述,判断图文之间的相关性;
- Collaboration Filtering:输入一个协同图(二分图),预测两侧节点之间的关系;
Graph Generation Modeling
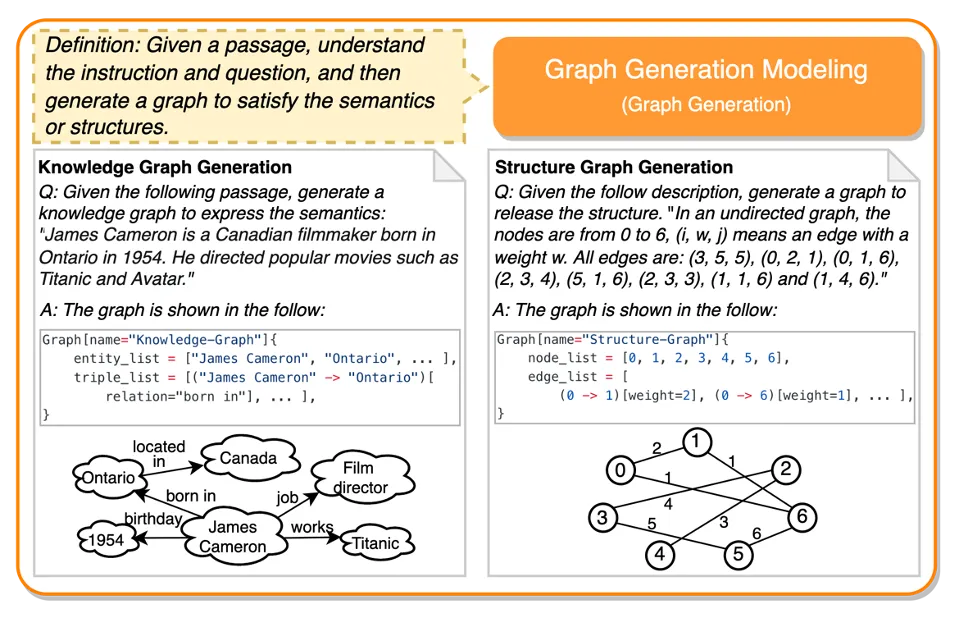 图生成建模旨在让大模型根据指令生成一个Graph。生成的过程等价于生成Code。
图生成包含两个类别的任务,分别是根据文本生成一个图,类似于信息抽取和知识图谱构建;另一个任务则是生成一个结构图。
图生成建模旨在让大模型根据指令生成一个Graph。生成的过程等价于生成Code。
图生成包含两个类别的任务,分别是根据文本生成一个图,类似于信息抽取和知识图谱构建;另一个任务则是生成一个结构图。Graph Thought Modeling
 除了针对Graph进行理解和推理以外,对于普通的文本生成和推理任务也可以间接利用Graph。例如数学计算推理时,原始的Chain-of-Thought(CoT)是通过text-based reasoning chain的形式进行推理的,而我们可以敦促模型先生成一个计算图,然后再基于这个计算图生成答案。这一过程也类似于大模型Agent中的Planning环节。
除了针对Graph进行理解和推理以外,对于普通的文本生成和推理任务也可以间接利用Graph。例如数学计算推理时,原始的Chain-of-Thought(CoT)是通过text-based reasoning chain的形式进行推理的,而我们可以敦促模型先生成一个计算图,然后再基于这个计算图生成答案。这一过程也类似于大模型Agent中的Planning环节。
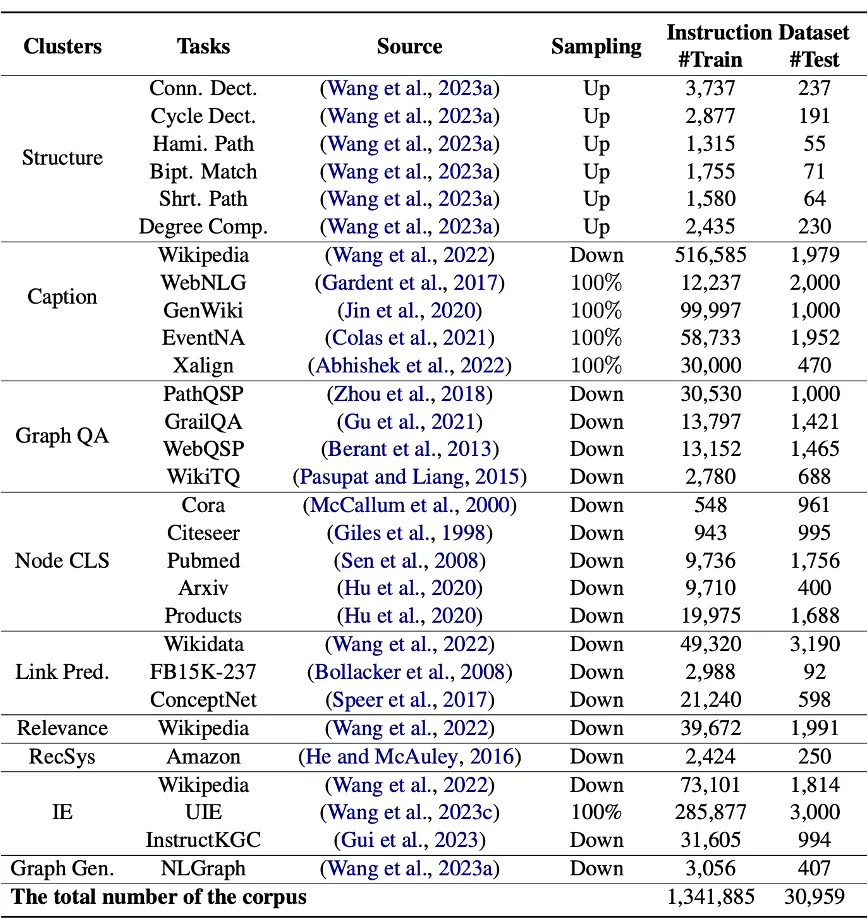
所有任务数据列举如下所示:
4、图偏好对齐
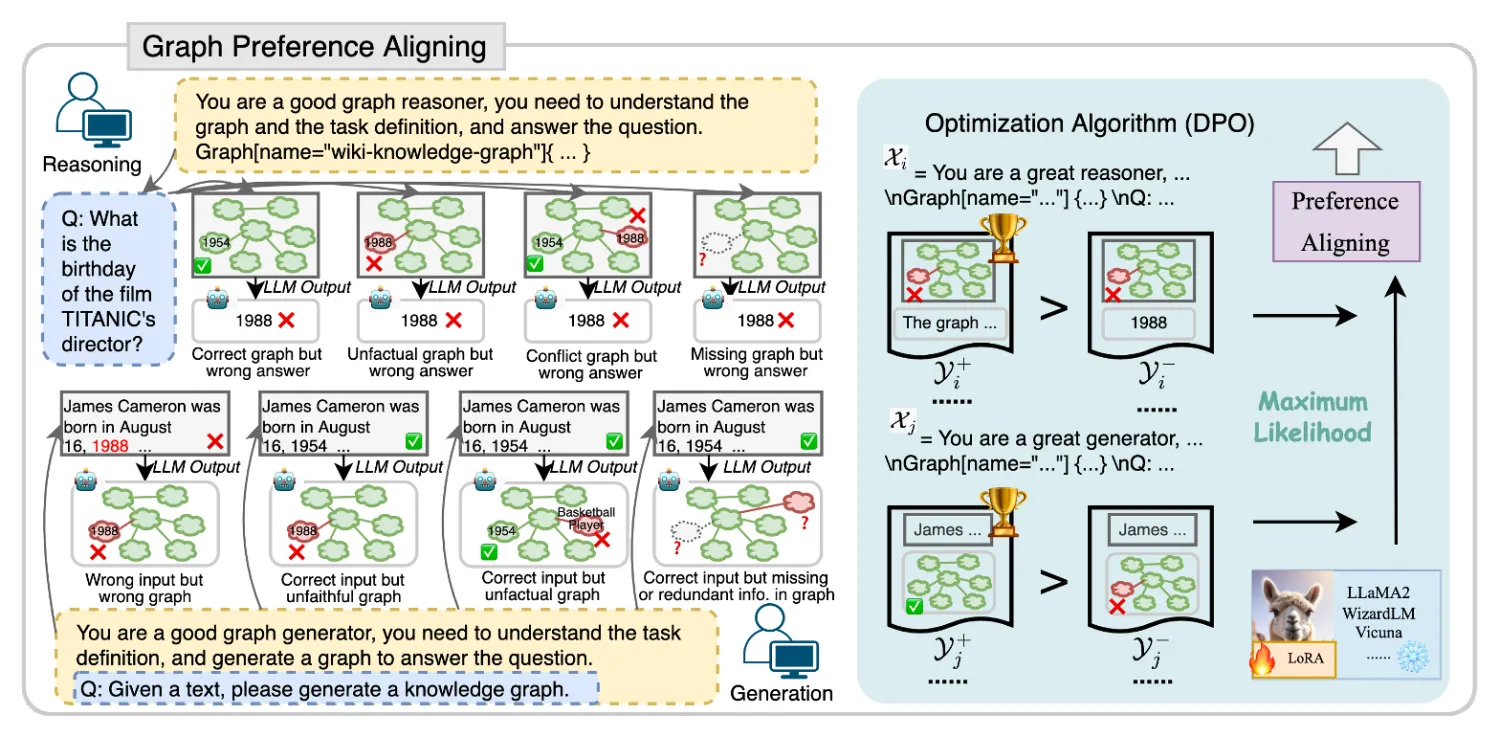
先前的很多面向Graph+LLM的工作,均忽略了Graph相关的偏好优化问题。我们发现LLM在针对Graph进行instruction-tuning阶段,同样存在一些偏好问题。我们认为除了LLM本身存在的harmless、helpless等问题外,针对Graph也依然存在如下问题:
- 输入的graph可能存在错误、冗余,或于大模型本身存在冲突的信息。
例如输入的graph中,存在冲突的关系,例如a -> b [relation=”r”], b -> a [relation=”r”] 输入的graph(尤其是知识图谱等),存在与真实知识冲突的,例如输入的graph 中国 -> 日本 [relation=”接壤”]
- 大模型生成的内容与输入的graph存在不一致(内部幻觉);
例如在KBQA时,大模型可能回答的答案可能不在子图中出现过。如果子图中没有,应该修正回答为“正确答案是xxx,不过如果只关注给定的图,则不存在答案”
- 大模型生成的内容与真实知识存在不一致(外部幻觉);
大模型生成的内容中有错误事实信息; 大模型生成graph时,出现胡编乱造 “给你三个节点,生成含有十条边的图”:这个问题很显然无法回答,需要让LLM优化。
为了避免过多的人工介入,构建偏好数据主要通过负采样的形式实现。负采样数据来源于两种途径:
- 启发式构建:修改graph结构,从而获得错误的graph,其与对应的文本不一致;
- ChatGPT改写:设计instruction,让模型编造一个与graph信息不一致的文本;
ps:需要获得错误的文本区间
提出两种non-reward的图对齐训练方法:Graph-based DPO(GDPO),即利用DPO的优化算法,根据上述两个graph存在的特性,构建pair数据。
五、实验
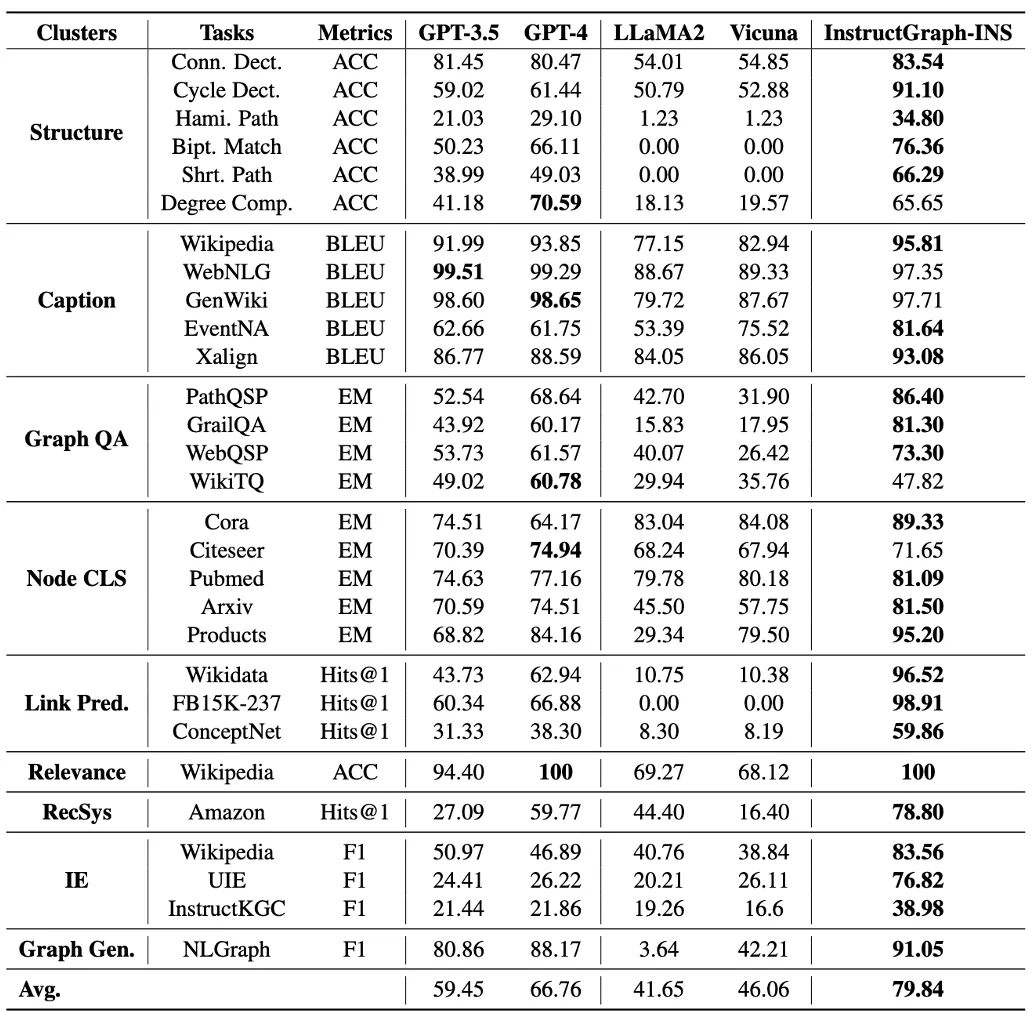
实验中,挑选LLaMA2-7B作为基座进行模型微调和对齐。整体实验如下图所示,InstructGraph的总体性能超越GPT-4。超越了GPT-4约13%,超越GPT-3.5约38%。
针对信息抽取任务的图生成任务,进行了较为细粒度的评估。生成一个图通常包含两个角度,一个是判断实体/节点的准确性、另一个是实体/节点之间关系的准确性,结果如下图所示:
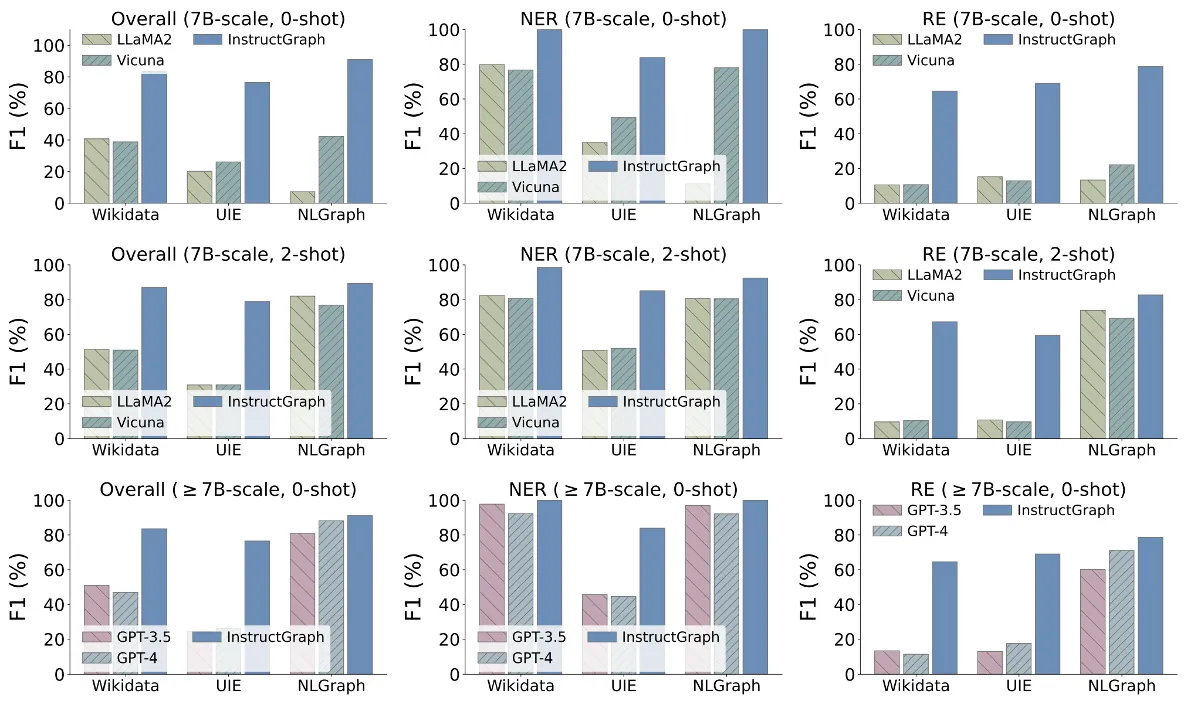
针对偏好对齐训练后的模型,实验结果如下所示:
 可发现,经过偏好对齐调优后的模型性能可以进一步得到提升,提升效果接近10%。
此外,InstructGraph在通用的NLP任务上效果也能够保持与LLaMA2相似的结果。
可发现,经过偏好对齐调优后的模型性能可以进一步得到提升,提升效果接近10%。
此外,InstructGraph在通用的NLP任务上效果也能够保持与LLaMA2相似的结果。