
OS-Atlas:面向通用 GUI Agent 的基础动作模型

论文题目:OS-ATLAS: A Foudation Action Model For Generalist GUI Agents
作者单位:上海AI Lab、上海交通大学、香港大学、MIT
论文地址:https://arxiv.org/pdf/2410.23218
项目地址:https://osatlas.github.io
开源地址:https://huggingface.co/OS-Copilot/
1 研究背景与动机
随着大语言模型 (LLM) 和多模态大模型 (VLM) 的发展,许多面向手机、电脑等智能设备的智能体研究开始涌现,研究者们希望在这些场景下通过大模型为智能设备赋能,将冗杂的人工操作转换成口头化的语言表达和自动化的机器执行,达到智能体自动托管的目的。近期,图形用户界面智能体 (GUI Agent) 的开发逐渐成为一个重要方向,研究者们试图以 GUI 为基础范式构建数字化智能体 (Digital Agent)。当前, VLM-based GUI Agent 通常以屏幕截图和任务指令为输入,完成复杂的决策任务。
GUI Agent的核心组件是Action Model:将自然语言指令转化为可执行的动作指令(例如,在屏幕中点击某个位置)。 然而,现有的开源GUI Action Models普遍存在两大局限:(1)GUI元素定位(GUI Grounding)能力较弱;(2)无法泛化到OOD场景。这些局限性主要归因于:(i)现有的VLM几乎没有在GUI屏幕截图上进行预训练;(ii)现有训练数据集内容格式各异,影响泛化性。
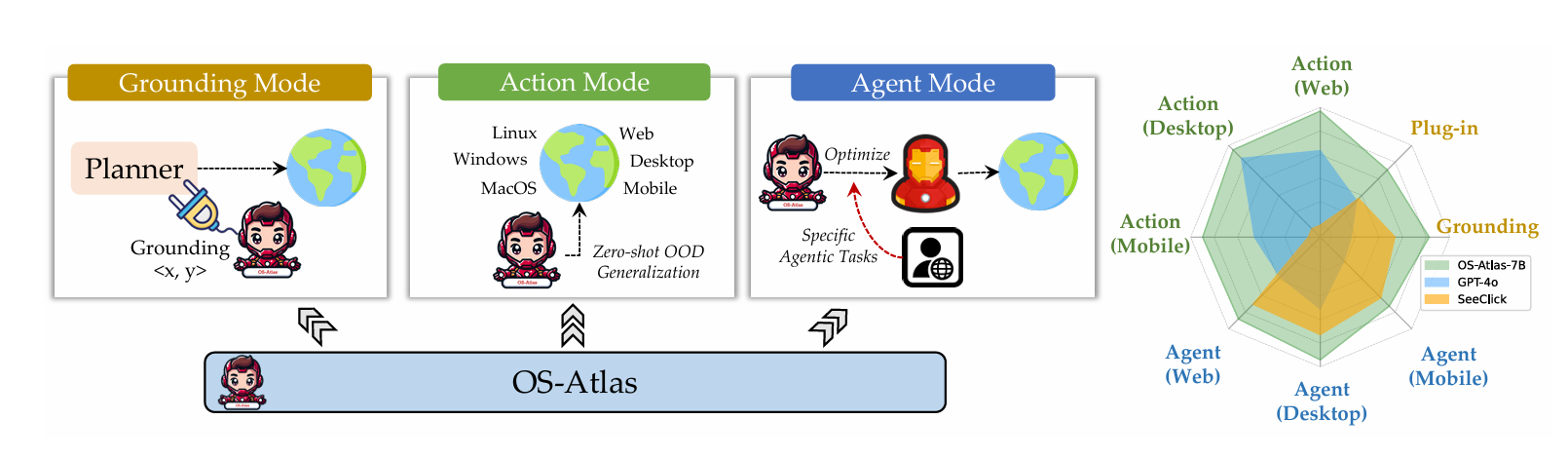
为了应对上述不足,我们开发了 OS-Atlas系列,专为 GUI Agent 设计的基座动作模型(Foundation Action Model)。 该系列模型包含4B和7B两个参数版本。 OS-Atlas主要具备三项重要能力模式(如下图所示):
- GUI Grounding Mode:支持与先进规划器(Planner)协作,完成真实环境中的挑战性任务。
- Action Mode:将自然语言指令转化为可执行的动作指令,支持多平台、多系统、多应用场景(Windows、Linux、MacOS、Android、Web)。
- Agent Mode:支持用户自主训练,构建专有化的GUI智能体。
除此以外,本工作还开发了跨平台GUI Grounding数据合成工具,并开源了迄今为止最大的GUI Grounding数据集,包含230万张屏幕截图和超过1300万个GUI元素。
2 数据采集与合成
当前 GUI Agent 的训练从数据角度出发,主要面临以下问题: (1) 训练数据可获取规模不足,且各个平台 (Web, Desktop, Mobile) 因数据收集的难度不同而导致数据量分布不均;(2) 缺少针对真实 GUI 任务场景下的高质量合成数据和轨迹数据。
为了解决这些问题,我们搭建了一个多平台的 GUI 数据生成工具库,并通过采集得到的数据构建和开源了一个跨平台的 GUI 语料库(包含超过 1300 万个 GUI 元素)。针对不同平台,我们设计了特定的数据采集来源和方式:
- 网页端: 先从 Common Crawl 收集大量 URL,再获取每个 URL 包含的网页信息。
- 桌面端: 分成 Windows, Linux 和 MacOS 三个系统进行构建,使用随机游走(random walk) 策略和脚本筛选相结合的方式采集真实操作系统环境下的屏幕截图和动作信息。
- 手机端: 以 AndroidWorld 环境为基础开发并在环境中采集了大量的 Android 数据。
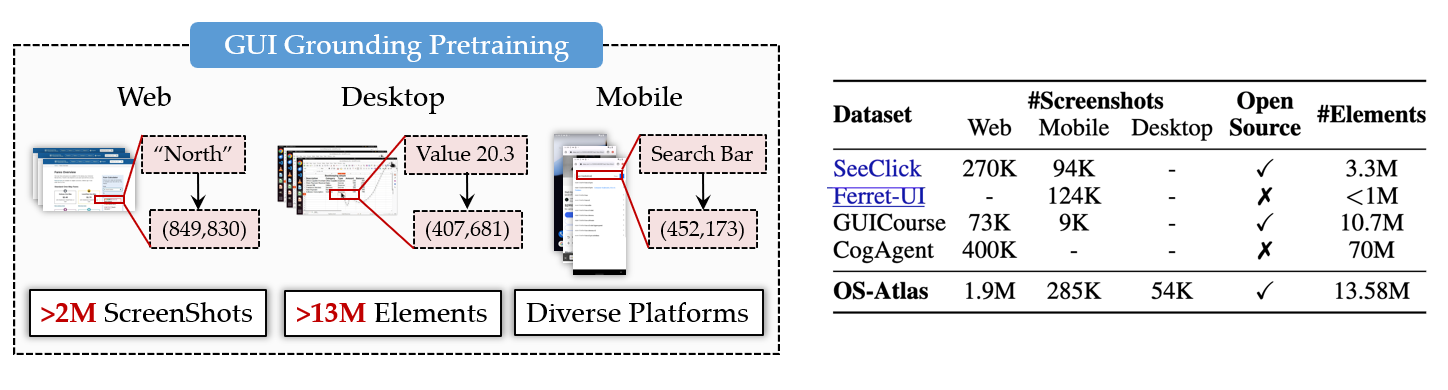
得益于我们的数据生成工具库,与先前的工作相比,OS-Atlas 获取了更为庞大和多样的 GUI 数据,并且这些数据也在我们后续的训练和实验中被证明了是非常高质量和有效的。
3 模型训练
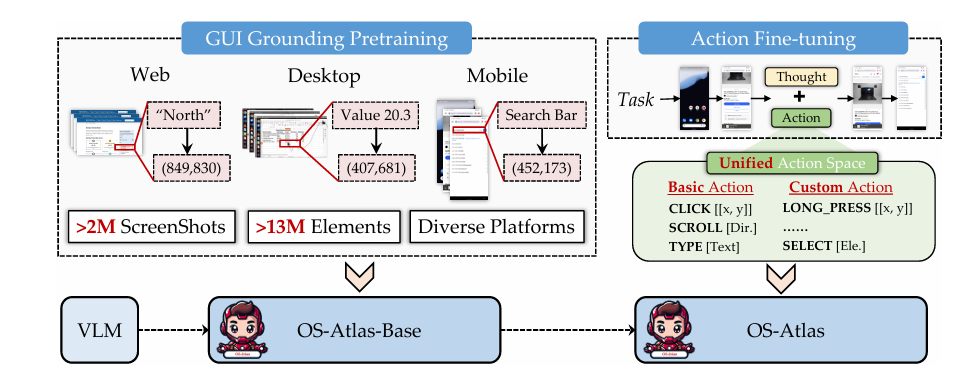 我们分别使用了InternVL2-4B 和 Qwen2VL-7B-Instruct模型作为初始基座。OS-Atlas 的训练可以分为两个阶段: (1) GUI Grounding 预训练; (2) Action数据微调。
我们分别使用了InternVL2-4B 和 Qwen2VL-7B-Instruct模型作为初始基座。OS-Atlas 的训练可以分为两个阶段: (1) GUI Grounding 预训练; (2) Action数据微调。
3-1 GUI Grounding 预训练
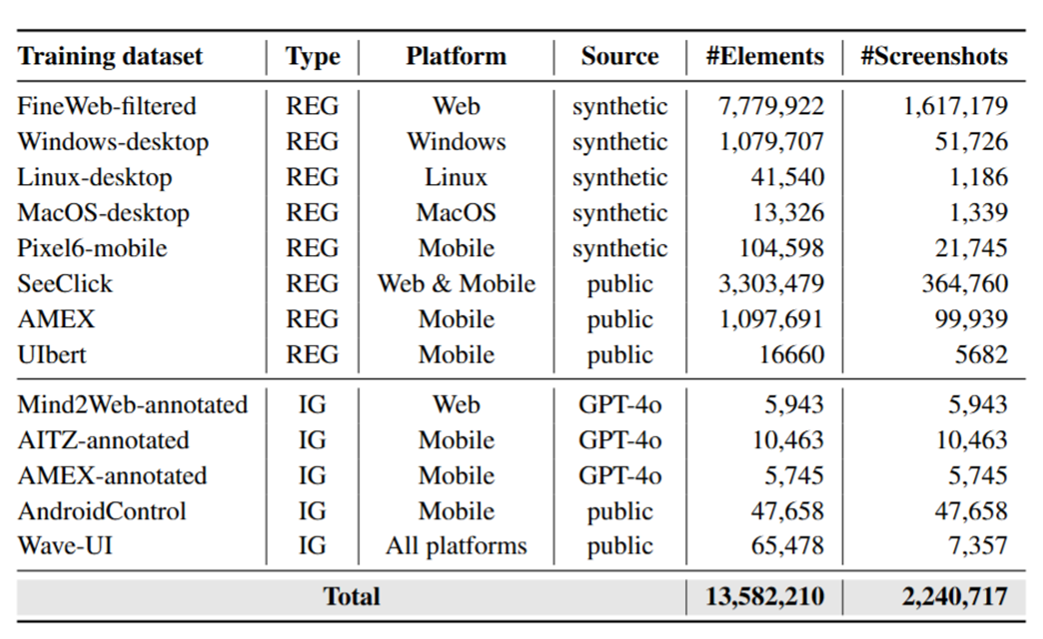
在 GUI Grounding 预训练阶段,我们整合了现有的开源数据和我们通过搭建工具库生成的数据,并将其组织成了 REG(Referring Expression Grounding) 和 IG(Instruction Grounding) 两种类型。
REG 数据通常容易获取,可表示为<screenshot, element referring expression, element coordinate>三元组,主要包含截图、对元素的直接描述和对应的坐标信息,而 IG 数据则需通过人工或 GPT-4o 等模型标注的方式得到,可表示为<screenshot, instruction, element coordinate>三元组, 与 REG 数据最大的不同便是通过一个指令或任务来间接描述需要定位的元素。
这个阶段最终使用了包含约230万张截图(约1350万的元素信息)的图文对数据进行训练,预训练得到的模型记为 OS-Atlas-Base,其拥有出色的 GUI Grounding 能力。
3-2 Action 微调
为了使模型进一步具备Action Mode的能力,我们对 OS-Atlas-Base 进行了 Action Finetuning, 使得其能够根据不同场景中的自然语言指令,输出相应的执行动作。 在具体实现中,本工作首先统一了GUI Agent的动作空间(Unify Action Space),解决了跨平台操作定义不一致的问题。 在统一的动作空间中,我们定义了通用的动作类型和各平台特有的动作类型,并通过调整运行时的 prompt,以支持OS-Atlas的跨平台使用。 基于动作空间的格式定义,本工作收集了现有的训练数据集(如AMEX,AITZ,Mind2Web等),并将它们转化为统一的格式进行微调。最终,得到GUI场景下的基座动作模型OS-Atlas。
4 主要实验结果
4-1 GUI Grounding 能力评测
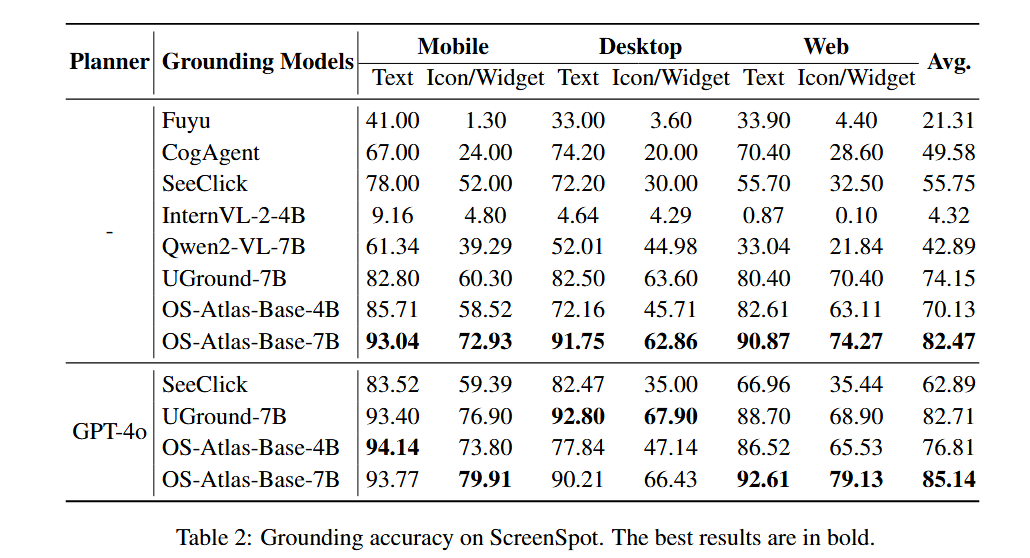
作为GUI Agent的核心能力之一,评测模型的 GUI Grounding 能力尤为重要。本工作引入当前使用最广泛的的ScreenSpot作为评测基准。 为了全面地证明OS-Atlas的优越性,本工作采用了直接推理和接入 GPT-4o Planner 两种评测方式。 结果表明,OS-Atlas-Base 大幅提升了先前的SOTA性能。特别地,在单模型直接推理的设定下,OS-Atlas在多平台的平均性能上超越同等量级的 UGround-7B (ICLR’25 Oral) 模型8.32%。
同时,在评测中我们也发现了 Screenspot 测试集中的一些错误数据,我们对此进行了人工纠正并发布了修正版的 Screenspot-V2。
4-2 真实 OS 环境评测
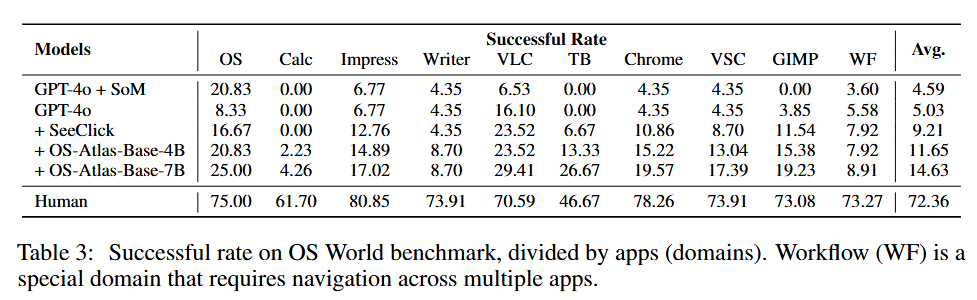
除了静态的Grounding数据集评测之外,我们也引入了更有挑战性的真实场景 OSWorld 对OS-Atlas进行了在线评测。 在测试中,我们以 GPT-4o 为 Planner,OS-Atlas 为 Grounder 构建简易 Agent。 结果显示,OS-Atlas 将GPT-4o的性能提升超过9%,同时也远超先前的Grounding SOTA 模型 SeeClick。 这也应证了 GUI Grounding的能力对提升GUI Agent在下游场景中的执行性能起着至关重要的作用。
4-3 下游 GUI 任务能力
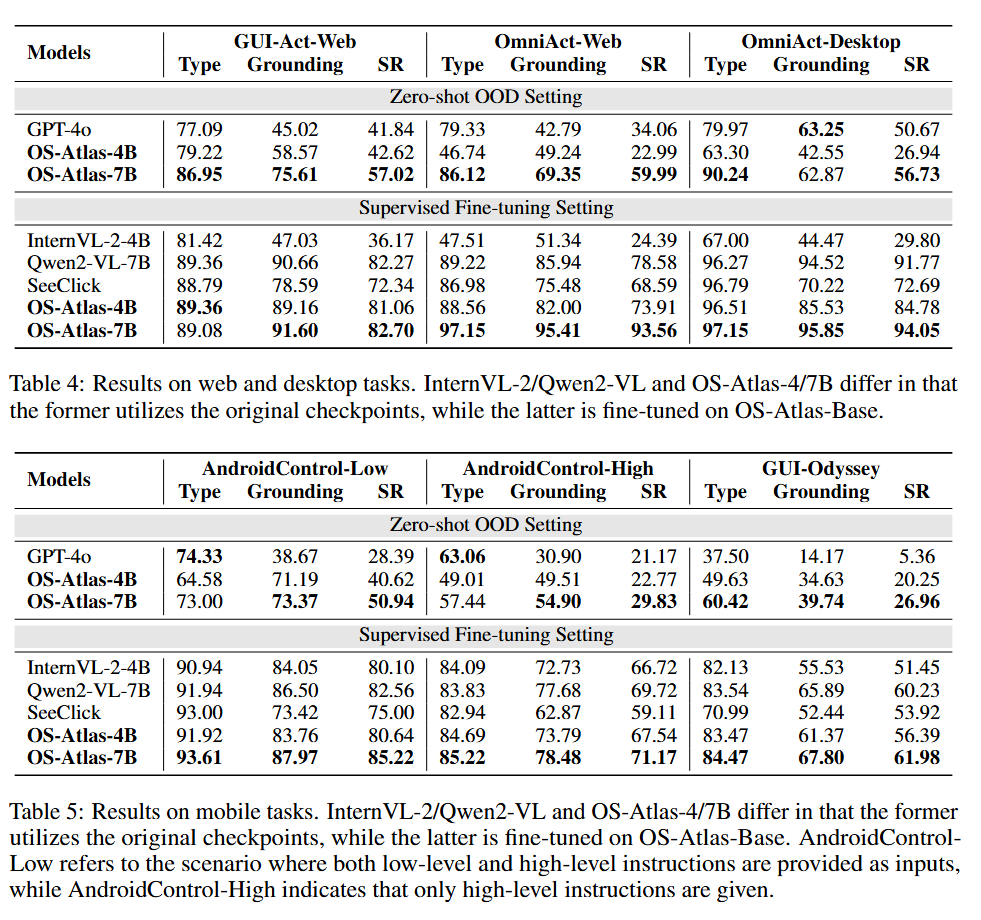
本工作也进行了大量实验来证明模型在 Action Mode 和 Agent Mode 上的巨大使用价值。我们采用了6个流行的下游数据集进行评测,涵盖了Web、Desktop和Mobile的场景。 针对 Action Mode,本工作设计了Zero-shot OOD Setting, 模型需要直接依据自然语言指令,来生成可执行的动作。由于当前的开源模型不具备零样本泛化的能力,我们将OS-Atlas与GPT-4o进行对比。结果显示,我们的开源基座动作模型 OS-Atlas ,在跨平台的多个数据集中大幅度超越了GPT-4o,解决了当前GUI模型OOD泛化能力不强的局限性。 针对 Agent Mode,本工作设计了 Supervised Fine-tuning Setting,通过特定数据集的微调,构建GUI Agent来完成决策任务。 与先前的SOTA模型SeeClick对比,OS-Atlas在动作类型匹配(Type)、元素定位(Grounding)和任务成功率(SR)指标上,取得了一致的优越性。尤其对于Omniact网页端和桌面端的场景,OS-Atlas更是领先SeeClick超过20个百分点。
5 分析实验
5-1 数据有效性
为了证明我们数据的有效性,我们从以下两个问题出发进行了实验论证: (5-1-1) 扩大数据量是否会持续提升模型的 GUI Grounding能力? (5-1-2) 多平台的数据收集以及引入高质量 IG 数据是否有其必要性?
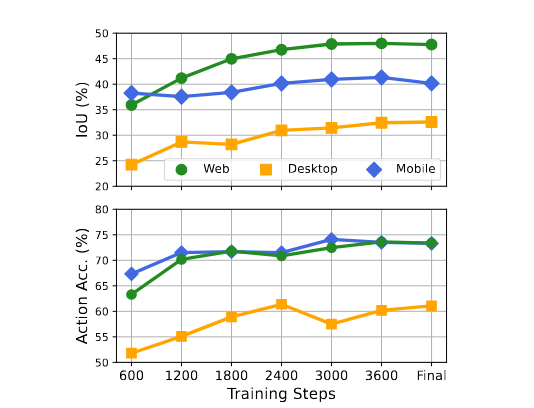 对于(5-1-1), 我们用不同数据规模训练了多个 checkpoint,并使用 IOU 和准确率两个指标进行了测评,发现随着数据规模的不断扩大,模型的 Grounding 能力整体呈现上升趋势。
对于(5-1-1), 我们用不同数据规模训练了多个 checkpoint,并使用 IOU 和准确率两个指标进行了测评,发现随着数据规模的不断扩大,模型的 Grounding 能力整体呈现上升趋势。
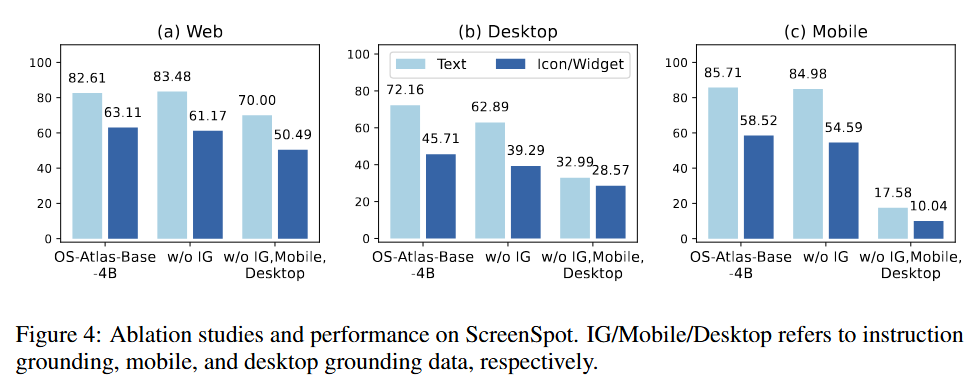 对于(5-1-2), 我们进行了数据消融实验,设计了三个对照组: (1) 使用全量数据训练; (2)去除 IG 数据进行训练;(3) 去除 IG 数据、手机端数据和桌面端数据进行训练。结果表明组(1)的效果要明显好于 (2) 和 (3),证明了 IG 数据以及多平台数据对于模型 Grounding 能力是很有必要的,为后续研究提供了参考。
对于(5-1-2), 我们进行了数据消融实验,设计了三个对照组: (1) 使用全量数据训练; (2)去除 IG 数据进行训练;(3) 去除 IG 数据、手机端数据和桌面端数据进行训练。结果表明组(1)的效果要明显好于 (2) 和 (3),证明了 IG 数据以及多平台数据对于模型 Grounding 能力是很有必要的,为后续研究提供了参考。
5-2 Scaling Law
在GUI Grounding的预训练实验过程中,我们还发现,下游任务(ScreenSpot)的性能并不是衡量Scaling law的理想指标。 这是因为GUI Grounding的评测无法准确反映真实的数据分布,且评估指标过于粗略(正确点击元素并不等价于完全正确地预测坐标)。
因此,为了更加严谨地展示GUI Grounding上的scaling law,我们拟合并绘制了损失函数的下降曲线,如下图。
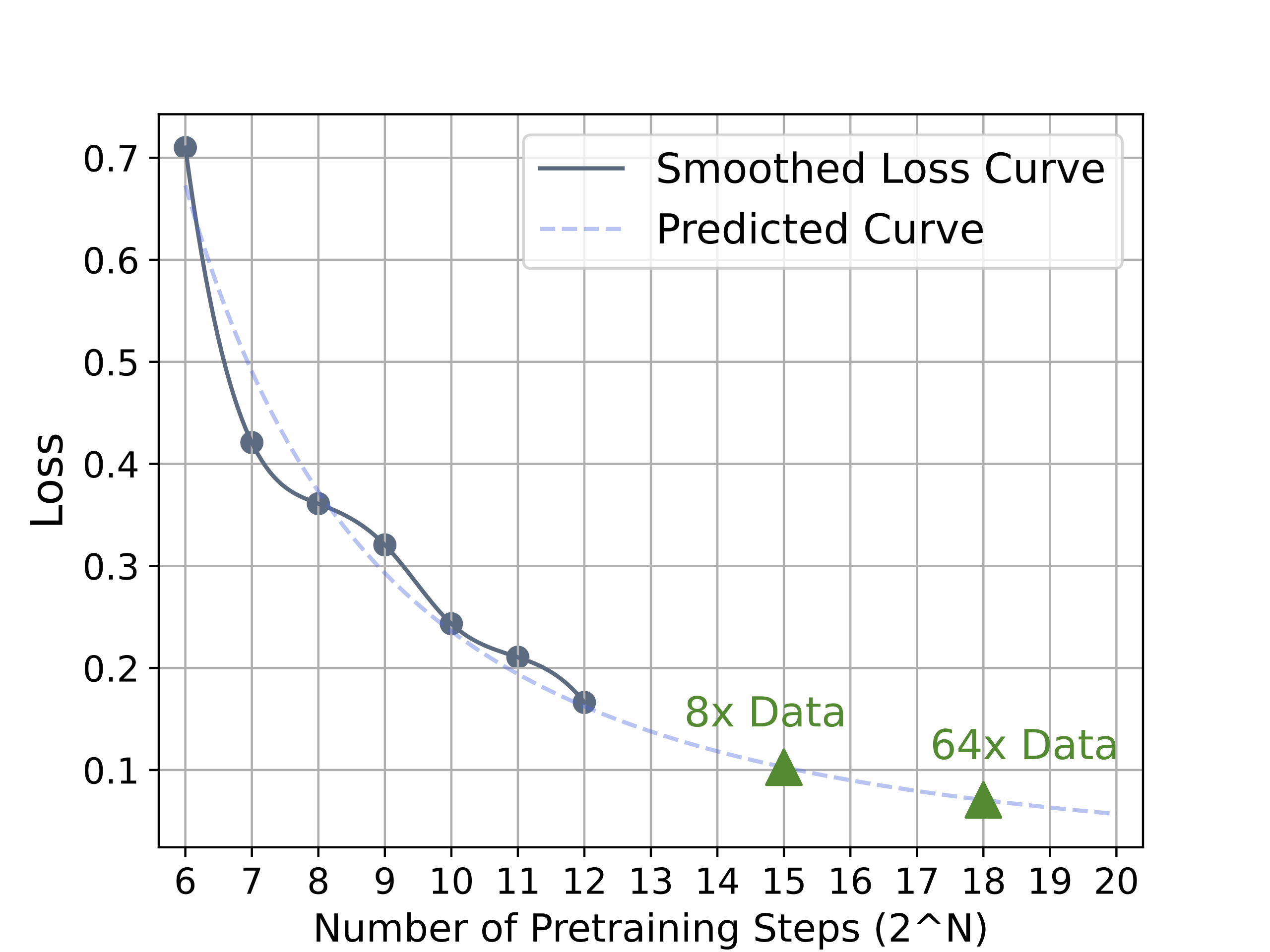
横轴表示模型训练步骤的数量,每个步骤包含1024个样本,每个样本最多包含15个GUI元素。深蓝色曲线表示平滑的损失轨迹。从图中可以观察到明显的下降趋势,表明持续扩展GUI Grounding预训练数据具有显著潜力。通过我们的scaling law分析,我们估算增加8倍的训练数据可以带来40%的相对损失减少。而将数据扩展64倍,可能会使损失相对减少57%。
6 总结
OS-Atlas 解决了现阶段 GUI Agent 在 Grounding 能力上的不足 以及OOD泛化能力上的局限性。本工作开源了OS-Atlas系列基础动作模型,包含4B和7B两个版本。同时,我们也开源了跨平台GUI Grounding数据合成工具,和截至目前最大的GUI Grounding数据集,包含230万张屏幕截图和超过1300万个GUI元素。这些开源成果将会为学术界和工业界构建更加先进的GUI Agent,提供有力帮助。