
大型语言模型真的擅长逻辑推理吗?(IEEE TKDE)
论文题目:Are Large Language Models Really Good Logical Reasoners? A Comprehensive Evaluation and Beyond
作者机构:西安交通大学、新加坡南洋理工大学
论文链接:https://arxiv.org/abs/2306.09841
数据集链接:https://github.com/DeepReasoning/NeuLR
背景
在人工智能和自然语言处理的浪潮下,大型语言模型(LLMs)正以前所未有的速度发展。它们在各种任务中表现出色,从文本生成到信息检索,几乎无所不能。然而,当涉及到真正的逻辑推理能力时,LLMs 真的能像人类一样进行严谨的推理吗?本研究针对这一问题,构建了系统化的评估体系,并提出了一系列创新性的分析方法,以揭示 LLMs 在逻辑推理方面的真实能力。
全面评估 LLMs 的逻辑推理能力
本研究首次在大规模逻辑推理任务上,对 LLMs 进行了全方位、多角度的评估。研究团队选取了 15 个典型的逻辑推理数据集,并将其划分为四种类别:
- 演绎推理(Deductive Reasoning):从一般性规则推导具体结论。
- 归纳推理(Inductive Reasoning):从具体实例归纳出普遍性规律。
- 溯因推理(Abductive Reasoning):在已有观察事实的基础上,推测最可能的解释。
- 混合推理(Mixed-form Reasoning):结合多种推理模式进行复杂推理。
此外,本研究涵盖了 3 个早期代表性 LLMs(text-davinci-003、ChatGPT 和 BARD)以及 4 个最新的 LLMs(LLaMA3.1-Chat、Mistral-Instruct-v0.3、Claude-3 和 GPT-4),通过精细化的指标对比,为行业提供了系统化的性能分析。
本测评工作的主要结果,可以可视化为以下热力图:
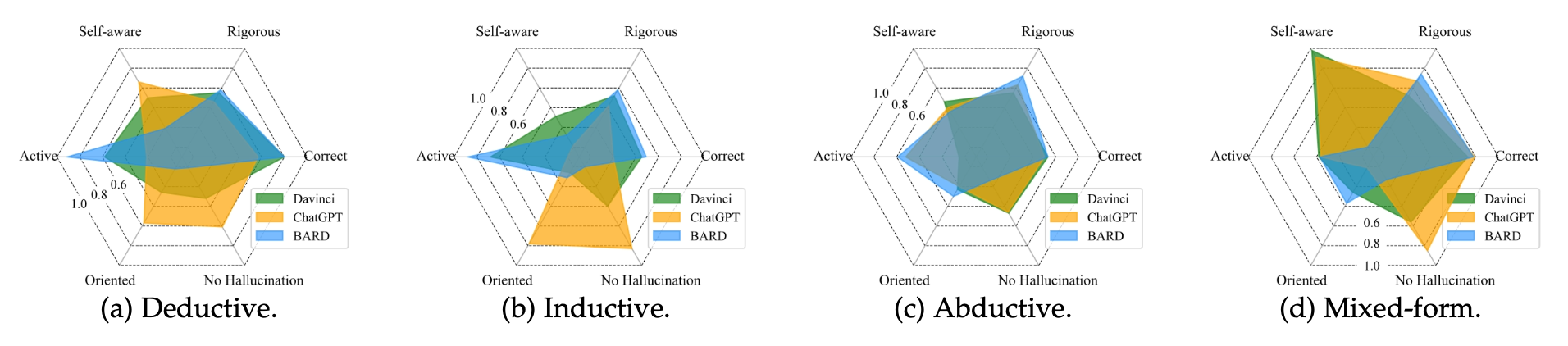
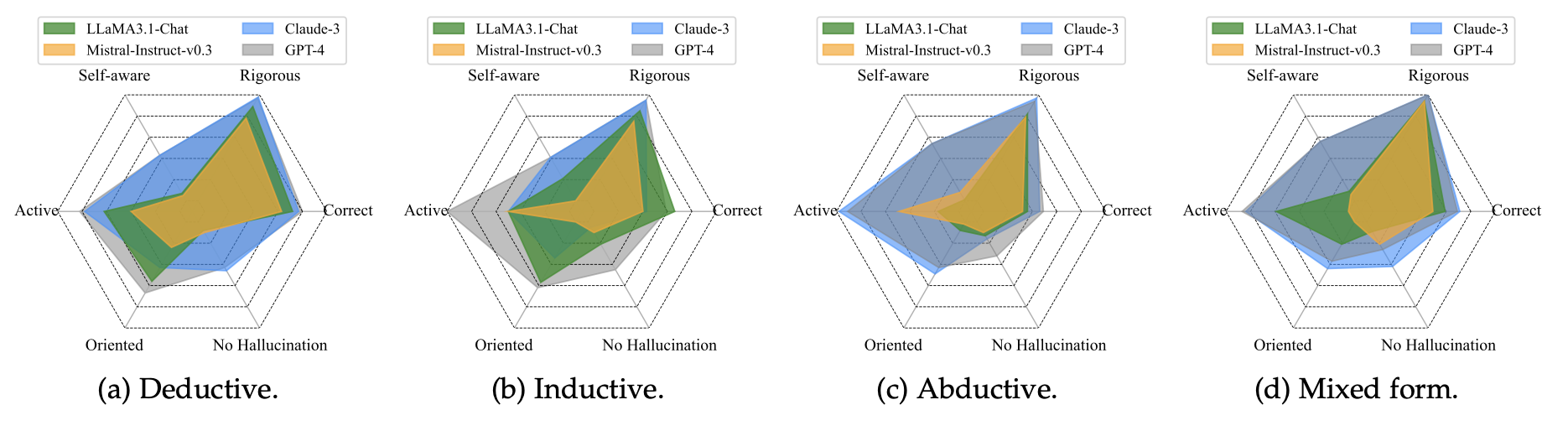
逻辑推理准确率评估
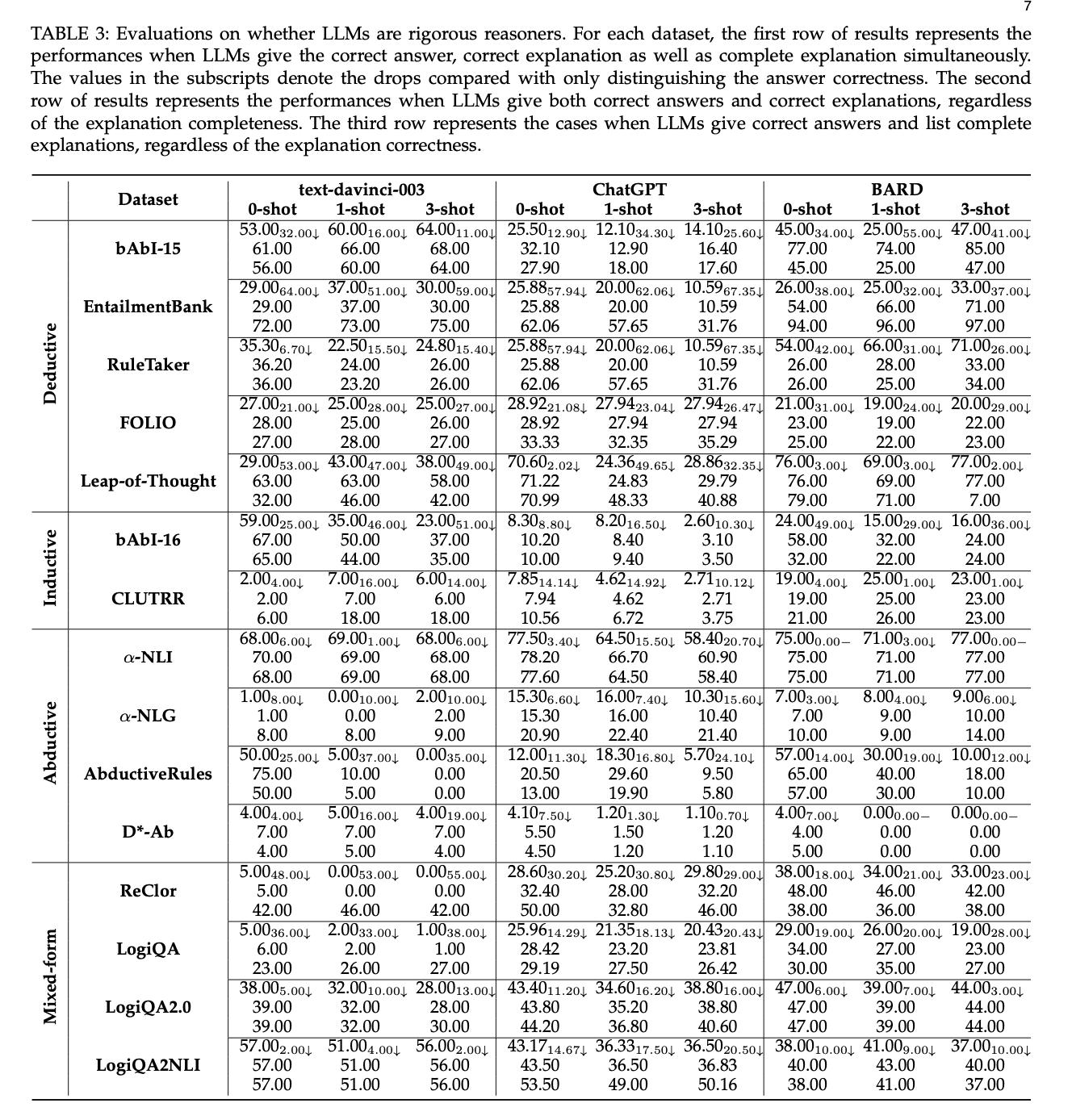
下表中展示了大语言模型在逻辑推理任务上的正确率评估结果。
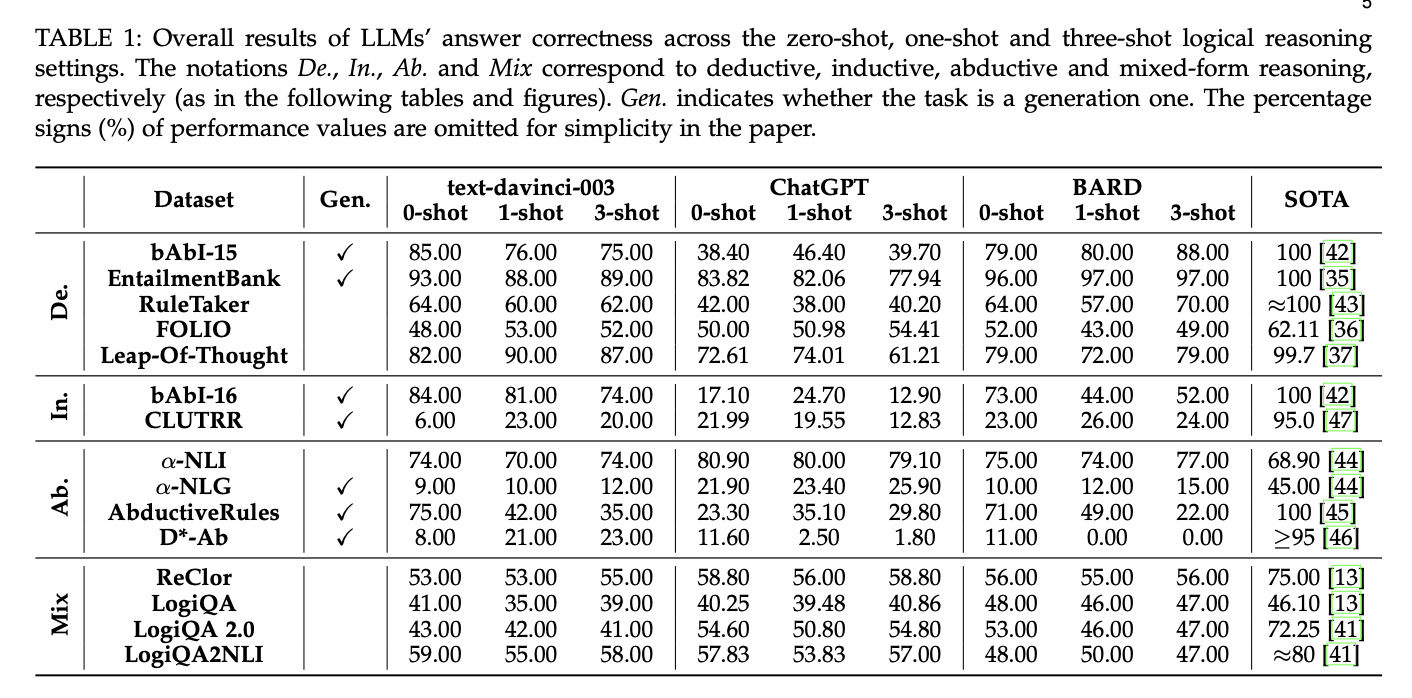
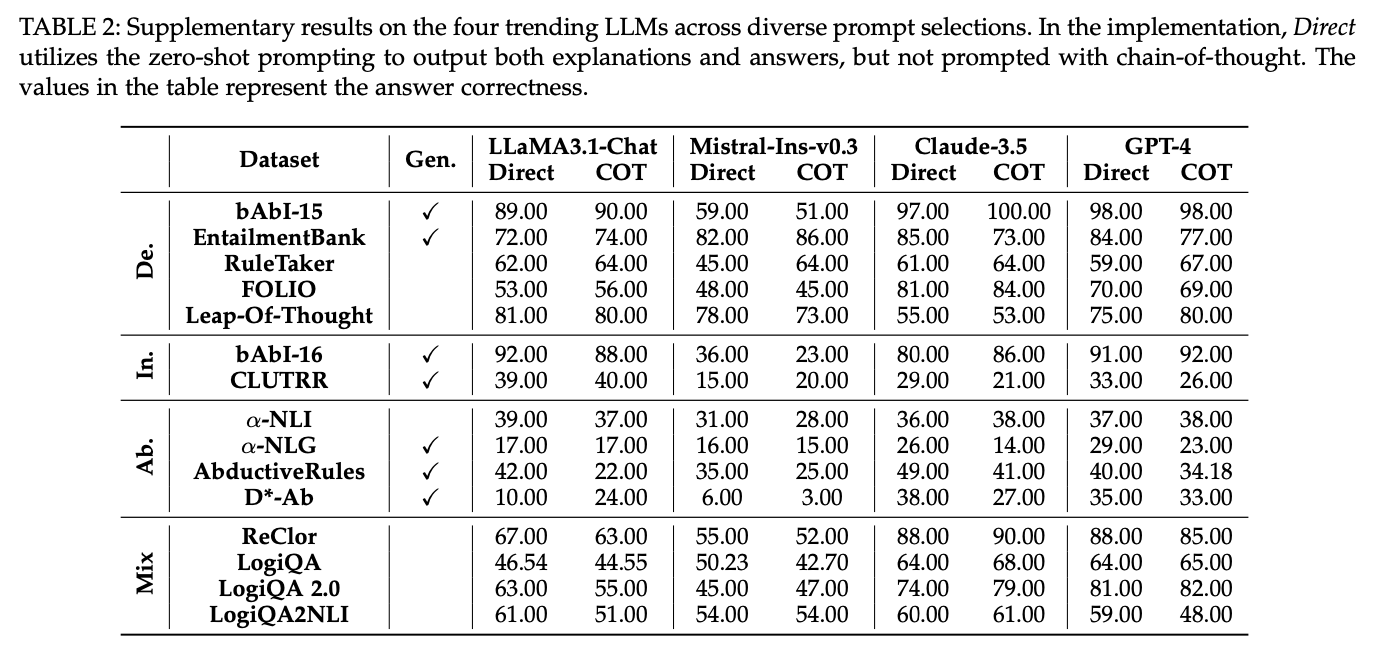
根据上述评估,可以得出了以下关键结论:
-
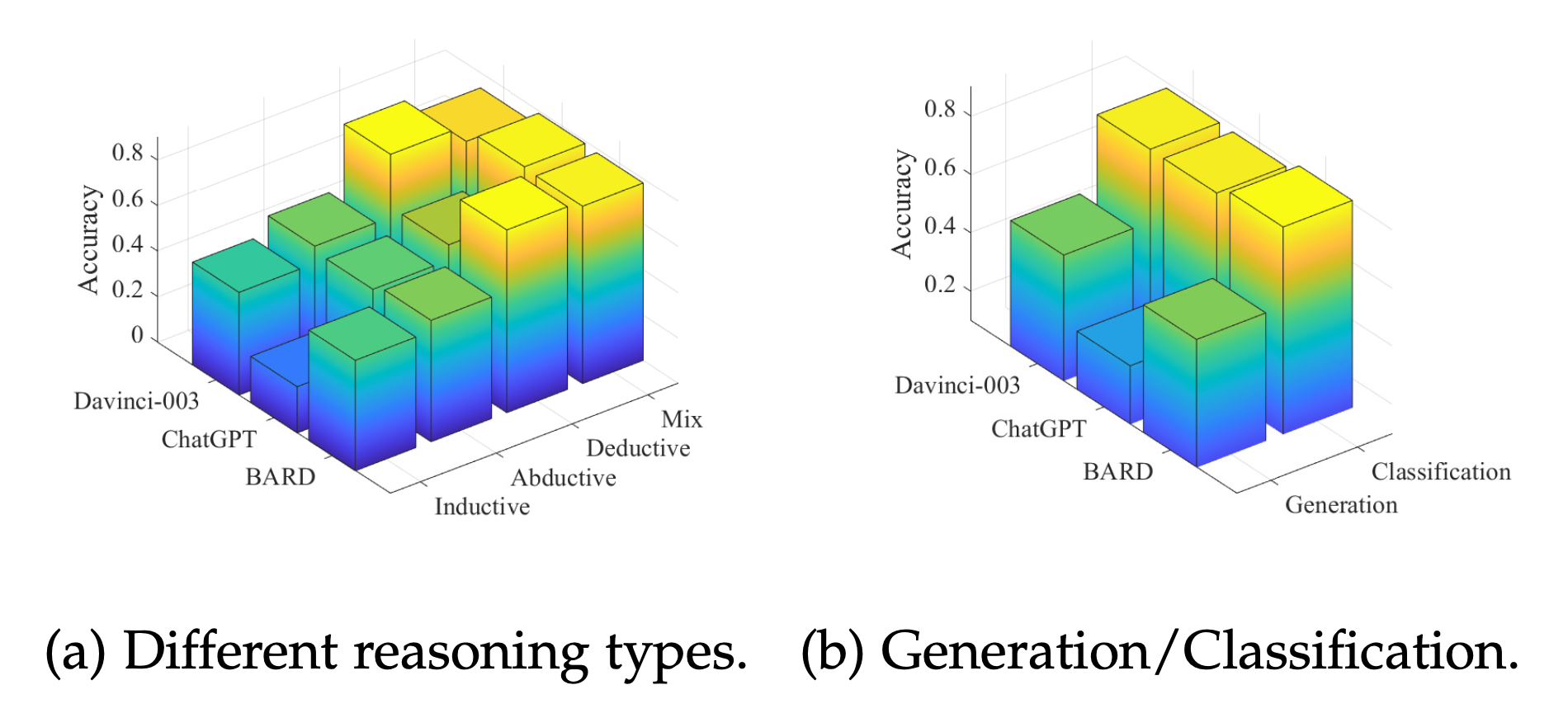
不同推理类型上的表现差异。 LLMs 在 演绎推理(Deductive Reasoning) 任务上整体表现较好,而在 归纳推理(Inductive Reasoning) 任务上表现较差。 在 溯因推理(Abductive Reasoning) 任务中,各模型的表现参差不齐,部分 LLMs 能够较好地推测最有可能的解释,但整体仍有较大提升空间。
-
Few-shot对逻辑推理结果的影响。 与 NLP 领域的其他任务不同,在逻辑推理任务中,Few-shot 推理并未显著提升 LLMs 的推理能力,甚至在某些情况下反而降低了模型的准确率。其中,在 归纳推理和混合推理 任务中,Few-shot 提示效果最不稳定,而在 演绎推理 任务中,少量 Few-shot 样本能略微提升模型表现。
-
不同任务形式的影响(生成 vs. 选择) 在 分类任务(选择题) 中,LLMs 的正确率普遍高于 生成任务(自由回答)。这表明 LLMs 在面对结构化选项时更容易做出正确推理,而在开放性任务中,其推理链条更容易出现错误或冗余内容。
创新性评估方法:超越简单准确率
与以往仅关注答案正确率的研究不同,本研究提出了一种更为细粒度的评估方法,从多个维度深入挖掘 LLMs 在逻辑推理方面的表现:
- 答案正确性(Answer Correctness):衡量 LLMs 是否能够给出正确答案。
- 解释正确性(Explanation Correctness):分析 LLMs 给出的推理解释是否符合逻辑。
- 解释完整性(Explanation Completeness):确保推理过程不遗漏关键信息。
- 解释冗余性(Explanation Redundancy):评估 LLMs 是否提供了过多或无关的解释。
更进一步,本工作首次对 LLMs 的逻辑推理错误进行了归因分析,提出了五大错误类别:
- 错误的证据选择(Wrong Evidence Selection)
- 推理过程中的幻觉(Hallucination in Reasoning)
- 缺乏推理(No Reasoning)
- 错误的推理方向(Mistaken Reasoning Perspective)
- 推理过程中的逻辑错误(Reasoning Process Mistake)
这一细化的错误归因体系,使得我们能够深入理解 LLMs 在逻辑推理任务中失败的根本原因,为未来的模型优化提供了明确方向。
细粒度分析实验
研究团队对 LLMs 在不同推理任务上的表现进行了深入分析,实验结果与分析如下。
1. LLMs是严谨的逻辑推理者吗?
虽然 LLMs 在某些任务上能够给出正确答案,但当同时要求提供完整且正确的解释时,模型的表现明显下降。例如,ChatGPT 在演绎推理任务 EntailmentBank 上的答案正确率达到 83.82%,但其能够提供正确且完整解释的比例仅为 25.88%。发现:LLMs 在溯因推理(abductive reasoning)环境中最擅长保持严谨的推理,而在演绎推理(deductive reasoning)和归纳推理(inductive reasoning)环境中则较为薄弱。
2. LLMs是自知的逻辑推理者吗?
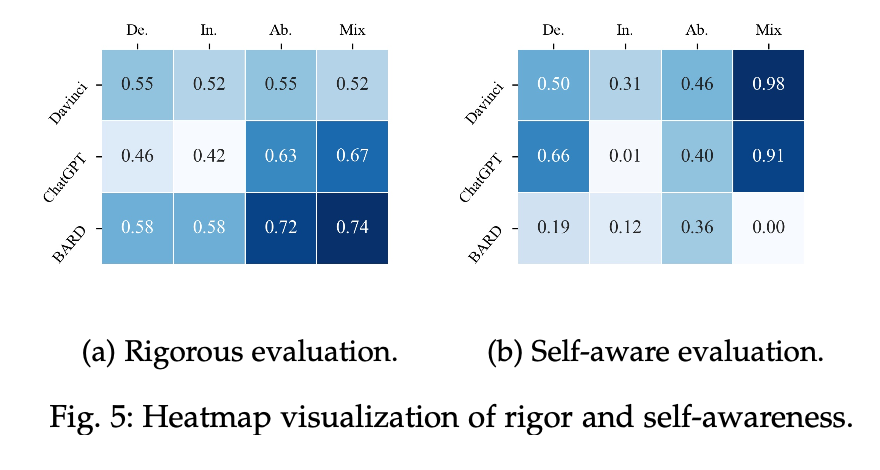
实验结果发现,在某些推理任务中,LLMs 生成的解释存在冗余问题,导致推理过程不够精炼。由于当前的大模型在后训练阶段引入了长思维链的优化,所以推理步骤冗余的现象较为普遍。尤其是在归纳推理上,模型的自知性较差。
3. LLMs存在明显的逻辑性谬误吗?
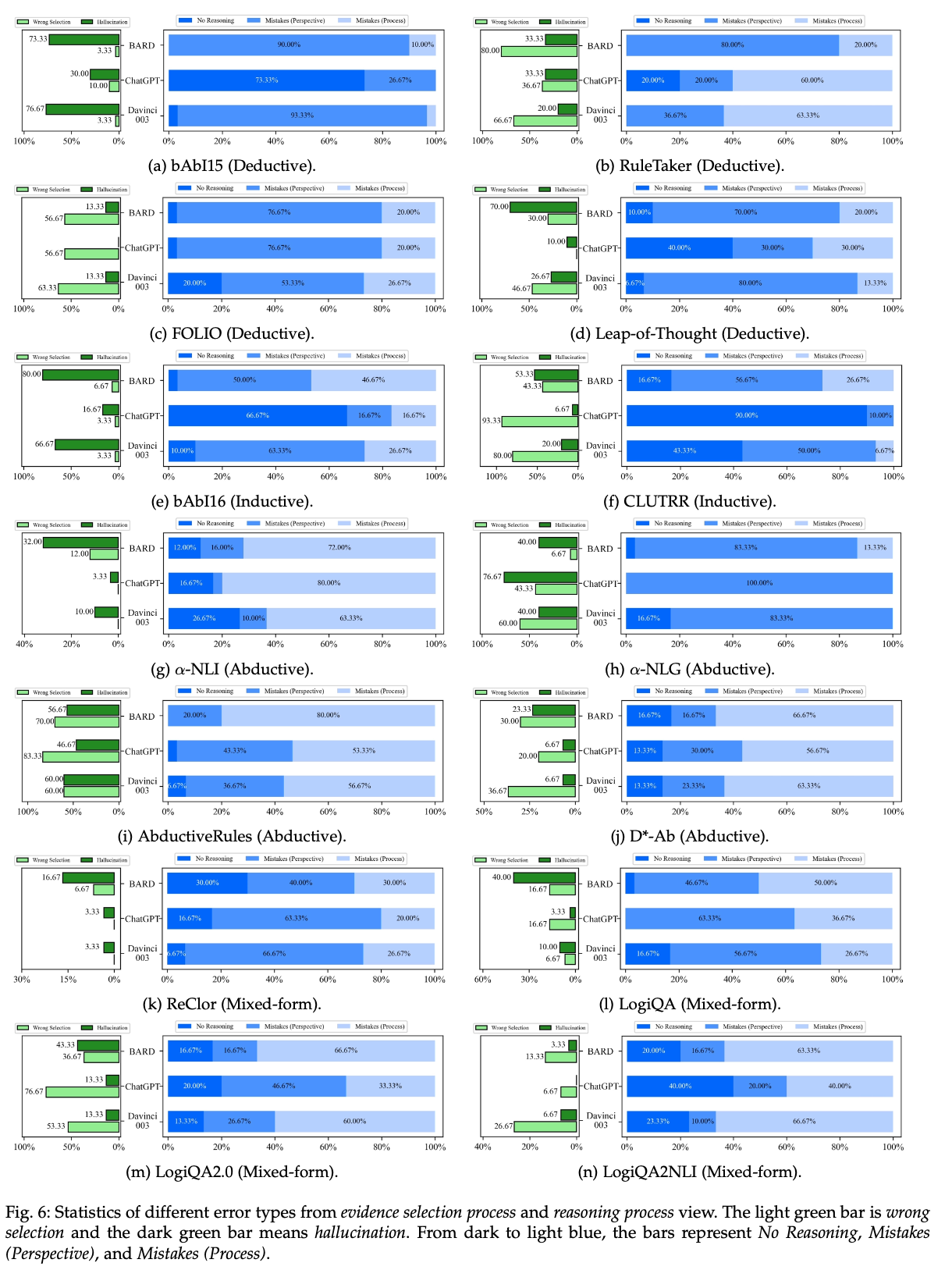
主动性分析:BARD 在推理过程中表现得最为“主动”,能够在较高比例的任务中进行完整推理。然而,ChatGPT 在某些情况下会表现出“懒惰”行为,仅列出已知事实而非进行有效推理。
方向性选择:实验发现,ChatGPT 虽然在逻辑推理任务中偶尔表现较弱,但在选择正确的推理方向上具有明显优势。在归纳推理任务中,BARD 和 text-davinci-003 更容易从错误方向展开推理,从而导致错误的推理结果。
幻觉问题:幻觉现象在 LLMs 的推理过程中依然存在。例如,在 AbductiveRules 任务中,LLMs 生成了与上下文矛盾的推理内容,其中 BARD 产生幻觉的比例高达 57%。相比之下,ChatGPT 在多数任务中能较好地避免幻觉问题。

全新数据集 NeuLR:消除内容偏见,中立评估逻辑能力
目前的逻辑推理评估数据集往往受到文本内容的影响,使得 LLMs 在推理时可能依赖于训练数据中的知识,而非真正的推理能力。为了解决这一问题,本研究提出了一个全新的中立性逻辑推理数据集——NeuLR,其核心特性包括:
- 内容中立:避免语言模型因训练数据的影响而产生偏见。
- 涵盖多种推理类型:包含 3,000 道逻辑推理题,涵盖演绎、归纳和溯因推理。
- 多跳推理(Multi-hop Reasoning):样本的推理步数从 1 到 5 不等,以测试 LLMs 在复杂推理任务中的表现。
实验结果表明,NeuLR 数据集能够更加公平地评估 LLMs 的逻辑推理能力,并揭示其在归纳和溯因推理方面的明显短板。
研究发现与未来方向
研究结果表明,尽管当前 LLMs 在逻辑推理方面取得了一定进展,但仍然存在诸多局限性。例如:
- 归纳推理能力较弱,难以从具体案例中归纳出普遍规律。
- 在多步推理任务中,推理链条容易断裂,导致答案错误。
- 由于训练数据的偏见,LLMs 在某些推理任务中倾向于过度自信,并生成幻觉内容。
本研究的系统评估不仅揭示了当前 LLMs 在逻辑推理方面的优势与不足,还为未来 LLMs 的优化方向提供了重要参考。随着 AI 领域的不断发展,我们期待更强大、更可靠的 LLMs 能够真正实现接近人类智能的逻辑推理能力!基于提出的全面的创新性评价体系,本工作也提供了自动化评测脚本,支持一键评测大模型的逻辑推理能力!